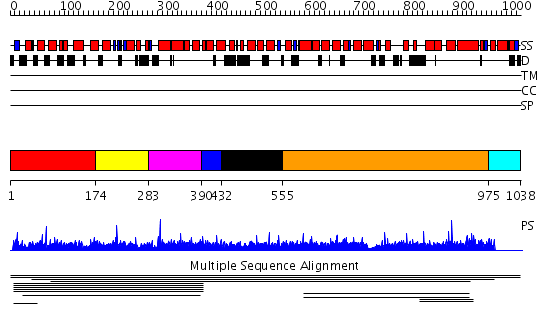
| Protein: | TTI1 |
| Organism: | Saccharomyces cerevisiae |
| Length: | 1038 amino acids |
| Reference: | Malmström L, et al. (2007) Superfamily assignments for the yeast proteome through integration of structure prediction with the gene ontology. PLoS Biol 5(4): e76. doi:10.1371/journal.pbio.0050076 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for TTI1.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..1038] | [1..1038] |
|
|
0.0 | [44..987] | [48..979] |
|
|
0.0 | [82..937] | [65..953] |
|
|
0.0 | [7..394] | [10..383] |
|
|
0.0 | [7..394] | [16..389] |
|
|
0.0 | [7..394] | [10..383] |
|
|
3.0E-95 | [598..936] | [799..1146] |
|
Region A: Residues: [1-173] |
1 11 21 31 41 51
| | | | | |
1 MNSDTNAFKD IRISCVELSR IAFLPTESFD PNSLTLLACL KKVEEKLSAY EDDSLSPKFA 60
61 DYVFVPIASL LKQPALGESQ TEYVLLIIFH LLRTCWSSNG KFSEQLGQQL FPLITFLVSS 120
121 DKDNQKLITR SDEFKYAGCL VLHQFFKSVR SQRYHKEFFS NSKPNLLPAL GHS
|
| Detection Method: | |
| Confidence: | 1.84 |
| Match: | 1i7wC |
| Description: | beta-Catenin |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [174-282] |
1 11 21 31 41 51
| | | | | |
1 VTILLKILEQ SPQNNELQFK ALASLEVLFQ DIISDGEMLS FILPGNVSVF AKILTKPGRQ 60
61 IHYKVCVRTL EVLAKLLVLV YDDFSLDIKV NKLTDIRELS DTKLKHEIN
|
| Detection Method: | |
| Confidence: | 1.84 |
| Match: | 1i7wC |
| Description: | beta-Catenin |
| Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| binding | 2.96084803796407 | bayes_pls_golite062009 |
| nucleic acid binding | 2.2915564382469 | bayes_pls_golite062009 |
| transcription regulator activity | 1.78626120336243 | bayes_pls_golite062009 |
| structural molecule activity | 1.66038601649515 | bayes_pls_golite062009 |
| DNA binding | 1.62962293446832 | bayes_pls_golite062009 |
| protein binding | 1.61131270705552 | bayes_pls_golite062009 |
| transcription factor activity | 0.931585995872658 | bayes_pls_golite062009 |
| translation regulator activity | 0.642878560112121 | bayes_pls_golite062009 |
| translation factor activity, nucleic acid binding | 0.620348955429476 | bayes_pls_golite062009 |
| translation initiation factor activity | 0.594620724124658 | bayes_pls_golite062009 |
| RNA binding | 0.243875756041061 | bayes_pls_golite062009 |
| protein kinase activity | 0.0590061807192209 | bayes_pls_golite062009 |
| cytoskeletal protein binding | 0.00858493919409042 | bayes_pls_golite062009 |
| transcription activator activity | 0.005251231402011 | bayes_pls_golite062009 |
|
Region A: Residues: [283-389] |
1 11 21 31 41 51
| | | | | |
1 QSFMFNGPIV LLRTDGKTHR DTSWLTATSG QINIALEAFI PKLLKRNNES IDEALATFVS 60
61 ILLTRCENSL NNCEKVLVST LVHLERDPMS KLPSHLVKLK EVVNEDL
|
| Detection Method: | |
| Confidence: | 1.84 |
| Match: | 1i7wC |
| Description: | beta-Catenin |
| Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [390-431] |
1 11 21 31 41 51
| | | | | |
1 HKLSDIIRFE NADRLSSLSF AITILEKNNE RDTMINEVVR CL
|
| Detection Method: | |
| Confidence: | 1.84 |
| Match: | 1i7wC |
| Description: | beta-Catenin |
| Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [432-554] |
1 11 21 31 41 51
| | | | | |
1 FESLNESIEP PSLINHKERI IEQSSQLTTT VNFENLESTN ALIALPRLSE DMSLKLKKFT 60
61 YHMGSLLLER HILNDVVTEL ISEQVDSPRT QKIVALWLST NFIKAMEKQP KEEEVYLQFE 120
121 SDA
|
| Detection Method: | |
| Confidence: | 1.84 |
| Match: | 1i7wC |
| Description: | beta-Catenin |
| Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [555-974] |
1 11 21 31 41 51
| | | | | |
1 NYSSSMVEEV CLIVLEFCNE LSQDISMEIE GKGIKKSDEF AVCTVLFSIE TICAVMREEF 60
61 QPELIDYIYT VVDALASPSE AIRYVSQSCA LRIADTLYHG SIPNMILSNV DYLVESISSR 120
121 LNSGMTERVS QILMVICQLA GYETIENFKD VIETIFKLLD YYHGYSDLCL QFFQLFKIII 180
181 LEMKKKYIND DEMILKIANQ HISQSTFSPW GMTDFQQVLN ILDKETQVKD DITDENDVDF 240
241 LKDDNEPSNF QEYFDSKLRE PDSDDDEEER EEEVEGSSKE YTDQWTSPIP SDSYKILLQI 300
301 LGYGERLLTH PSKRLRVQIL IVMRLIFPLL STQHNLLIRE VASTWDSIIQ CVLCSDYSIV 360
361 QPACSCVEQM IKYSGDFVAK RFIELWQKLC QDSFILKELR IDPTVHNHEK KSISKHVKFP 420
421
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [975-1038] |
1 11 21 31 41 51
| | | | | |
1 PVTENALVSM VHMVLEGVKI TEYLISEAVL EQIIYCCIQV VPVEKISSMS LIVGDIVWKI 60
61 RNIN
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.