| Protein: | hlh-2 |
| Organism: | Caenorhabditis elegans |
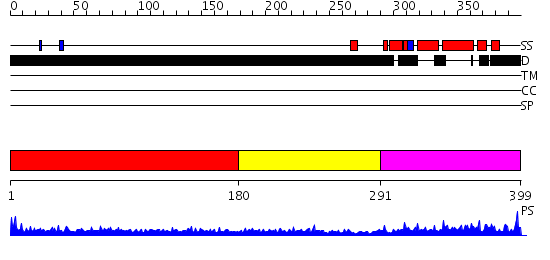
| Length: | 399 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for hlh-2.
| Description | E-value | Query Range |
Subject Range |
|
|
188.0 | [0..10] | [373..819] |
|
Region A: Residues: [1-179] |
1 11 21 31 41 51
| | | | | |
1 MADPNSQLTS ATTVATAAIA QPQVMLPNAY DYPYNIDPTT IQMPDYWSGY HLNPYPPMQT 60
61 TDIDYSSAFL PTHPPTETPA SVAAPTSATS DIKPIHATSS TSTTAPSTAP APTSTTDVLE 120
121 LKPTTAPATN SAETSAIVAP QPLTNLTAPI DAMSSMYTWP QTYPGYLPPS EDNKASEAV
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [180-290] |
1 11 21 31 41 51
| | | | | |
1 NPYISIPPTY TFGADPSVAD FSSYQQQLAG QPNGLGGDTN LVDYNHQFPP AGMSPHFDPN 60
61 GYPGMTGMPP GSSASSVRND KSASRATSRR RVQGPPSSGI PTRHSSSSRL S
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [291-399] |
1 11 21 31 41 51
| | | | | |
1 DNESMSDDKD TDRRSQNNAR ERVRVRDINS AFKELGRMCT QHNQNTERNQ TKLGILHNAV 60
61 SVITQLEEQV RQRNMNPKVM AGMKRKPDDD KMKMLDDNAP SAQFGHPRF
|
| Detection Method: | |
| Confidence: | 1.82 |
| Match: | 1nkpA |
| Description: | Myc prot-oncogene protein |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| transcription regulator activity | 3.52515734914199 | bayes_pls_golite062009 |
| DNA binding | 3.21016883589545 | bayes_pls_golite062009 |
| nucleic acid binding | 3.15909910956342 | bayes_pls_golite062009 |
| transcription factor activity | 2.90093125513881 | bayes_pls_golite062009 |
| binding | 2.29757014970031 | bayes_pls_golite062009 |
| protein binding | 1.81946124321514 | bayes_pls_golite062009 |
| transcription activator activity | 1.77806752347571 | bayes_pls_golite062009 |
| sequence-specific DNA binding | 1.22261023465971 | bayes_pls_golite062009 |
| RNA polymerase II transcription factor activity | 1.09856580825267 | bayes_pls_golite062009 |
| transcription factor binding | 0.435480522052453 | bayes_pls_golite062009 |
| RNA polymerase II transcription factor activity, enhancer binding | 0.194129578991214 | bayes_pls_golite062009 |