| Protein: | EIF3CL, EIF3C |
| Organism: | Homo sapiens |
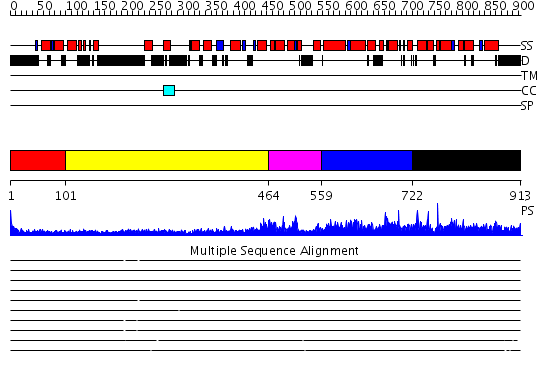
| Length: | 913 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for EIF3CL, EIF3C.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..913] | [108..1018] |
|
|
0.0 | [1..913] | [1..913] |
|
|
0.0 | [1..913] | [1..913] |
|
|
0.0 | [1..913] | [1..913] |
|
|
0.0 | [1..913] | [1..912] |
|
|
0.0 | [1..913] | [1..911] |
|
|
0.0 | [1..909] | [1..912] |
|
|
0.0 | [1..913] | [1..922] |
|
Region A: Residues: [1-100] |
1 11 21 31 41 51
| | | | | |
1 MSRFFTTGSD SESESSLSGE ELVTKPVGGN YGKQPLLLSE DEEDTKRVVR SAKDKRFEEL 60
61 TNLIRTIRNA MKIRDVTKCL EEFELLGKAY GKAKSIVDKE
|
| Detection Method: | |
| Confidence: | 4.221849 |
| Match: | 2i1jA |
| Description: | No description for 2i1jA was found. |
|
Region A: Residues: [101-463] |
1 11 21 31 41 51
| | | | | |
1 GVPRFYIRIL ADLEDYLNEL WEDKEGKKKM NKNNAKALST LRQKIRKYNR DFESHITSYK 60
61 QNPEQSADED AEKNEEDSEG SSDEDEDEDG VSAATFLKKK SEAPSGESRK FLKKMDDEDE 120
121 DSEDSEDDED WDTGSTSSDS DSEEEEGKQT ALASRFLKKA PTTDEDKKAA EKKREDKAKK 180
181 KHDRKSKRLD EEEEDNEGGE WERVRGGVPL VKEKPKMFAK GTEITHAVVI KKLNEILQAR 240
241 GKKGTDRAAQ IELLQLLVQI AAENNLGEGV IVKIKFNIIA SLYDYNPNLA TYMKPEMWGK 300
301 CLDCINELMD ILFANPNIFV GENILEESEN LHNADQPLRV RGCILTLVER MDEEFTKIMQ 360
361 NTD
|
| Detection Method: | |
| Confidence: | 19.69897 |
| Match: | 1i84S |
| Description: | Heavy meromyosin subfragment |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [464-558] |
1 11 21 31 41 51
| | | | | |
1 PHSQEYVEHL KDEAQVCAII ERVQRYLEEK GTTEEVCRIY LLRILHTYYK FDYKAHQRQL 60
61 TPPEGSSKSE QDQAENEGED SAVLMERLCK YIYAK
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [559-721] |
1 11 21 31 41 51
| | | | | |
1 DRTDRIRTCA ILCHIYHHAL HSRWYQARDL MLMSHLQDNI QHADPPVQIL YNRTMVQLGI 60
61 CAFRQGLTKD AHNALLDIQS SGRAKELLGQ GLLLRSLQER NQEQEKVERR RQVPFHLHIN 120
121 LELLECVYLV SAMLLEIPYM AAHESDARRR MISKQFHHQL RVG
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [722-913] |
1 11 21 31 41 51
| | | | | |
1 ERQPLLGPPE SMREHVVAAS KAMKMGDWKT CHSFIINEKM NGKVWDLFPE ADKVRTMLVR 60
61 KIQEESLRTY LFTYSSVYDS ISMETLSDMF ELDLPTVHSI ISKMIINEEL MASLDQPTQT 120
121 VVMHRTEPTA QQNLALQLAE KLGSLVENNE RVFDHKQGTY GGYFRDQKDG YRKNEGYMRR 180
181 GGYRQQQSQT AY
|
| Detection Method: | |
| Confidence: | 2.14 |
| Match: | 1ufmA |
| Description: | Solution structure of the PCI domain |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| transcription regulator activity | 2.85334044543318 | bayes_pls_golite062009 |
| nucleic acid binding | 2.8293727459515 | bayes_pls_golite062009 |
| DNA binding | 2.66906990480864 | bayes_pls_golite062009 |
| binding | 2.5888309899403 | bayes_pls_golite062009 |
| transcription factor activity | 1.97506348695089 | bayes_pls_golite062009 |
| protein binding | 0.933833716716586 | bayes_pls_golite062009 |
| structural constituent of ribosome | 0.764002516817766 | bayes_pls_golite062009 |
| structural molecule activity | 0.756450227832198 | bayes_pls_golite062009 |
| sequence-specific DNA binding | 0.665091289283954 | bayes_pls_golite062009 |
| transcription activator activity | 0.542530812773621 | bayes_pls_golite062009 |
| transcription repressor activity | 0.423955395883599 | bayes_pls_golite062009 |