| Protein: | SMU1_ARATH |
| Organism: | Arabidopsis thaliana |
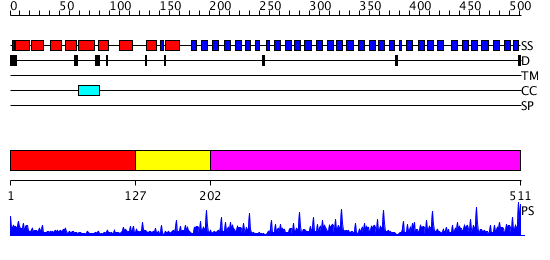
| Length: | 511 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for SMU1_ARATH.
| Description | E-value | Query Range |
Subject Range |
|
|
454.0 | [0..44] | [510..804] |
|
|
449.0 | [0..92] | [510..723] |
|
|
447.0 | [0..33] | [510..1011] |
|
|
444.0 | [0..61] | [509..191] |
|
|
441.0 | [0..42] | [510..1276] |
|
|
438.0 | [0..55] | [510..879] |
|
Region A: Residues: [1-126] |
1 11 21 31 41 51
| | | | | |
1 MALEIEARDV IKIMLQFCKE NSLNQTFQTL QSECQVSLNT VDSVETFISD INSGRWDSVL 60
61 PQVSQLKLPR NKLEDLYEQI VLEMIELREL DTARAILRQT QVMGVMKQEQ AERYLRMEHL 120
121 LVRSYF
|
| Detection Method: | |
| Confidence: | 10.522879 |
| Match: | 1uujA |
| Description: | N-terminal domain of Lissencephaly-1 protein (Lis-1) |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [127-201] |
1 11 21 31 41 51
| | | | | |
1 DPHEAYGDST KERKRAQIAQ AVAAEVTVVP PSRLMALIGQ ALKWQQHQGL LPPGTQFDLF 60
61 RGTAAMKQDV EDTHP
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [202-511] |
1 11 21 31 41 51
| | | | | |
1 NVLTHTIKFG KKSHAECARF SPDGQFLASS SVDGFIEVWD YISGKLKKDL QYQADESFMM 60
61 HDDPVLCIDF SRDSEMLASG SQDGKIKIWR IRTGVCIRRF DAHSQGVTSL SFSRDGSQLL 120
121 STSFDQTARI HGLKSGKLLK EFRGHTSYVN HAIFTSDGSR IITASSDCTV KVWDSKTTDC 180
181 LQTFKPPPPL RGTDASVNSI HLFPKNTEHI VVCNKTSSIY IMTLQGQVVK SFSSGNREGG 240
241 DFVAACVSTK GDWIYCIGED KKLYCFNYQS GGLEHFMMVH EKDVIGITHH PHRNLLATYS 300
301 EDCTMKLWKP
|
| Detection Method: | |
| Confidence: | 84.69897 |
| Match: | 2gnqA |
| Description: | No description for 2gnqA was found. |