| Protein: | gi|186509898, gi... |
| Organism: | Arabidopsis thaliana |
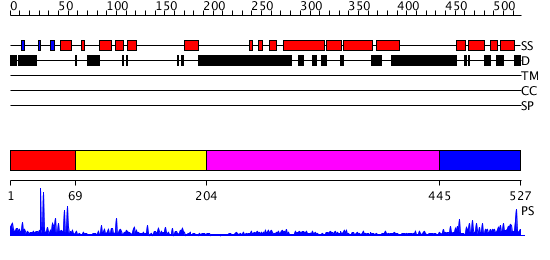
| Length: | 527 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for gi|186509898, gi....
| Description | E-value | Query Range |
Subject Range |
|
|
279.0 | [0..2] | [527..21] |
|
|
256.0 | [0..30] | [521..51] |
|
|
253.0 | [0..30] | [521..51] |
|
Region A: Residues: [1-68] |
1 11 21 31 41 51
| | | | | |
1 MYQAAFSKSS YMYQYIVGIE AGNERKPGLY CCNYCDKDLS GLVRFKCAVC MDFDLCVECF 60
61 SVGVELNR
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [69-203] |
1 11 21 31 41 51
| | | | | |
1 HKNSHPYRVM DNLSFSLVTS DWNADEEILL LEAIATYGFG NWKEVADHVG SKTTTECIKH 60
61 FNSAYMQSPC FPLPDLSHTI GKSKDELLAM SKDSAVKTEI PAFVRLSPKE ELPVSAEIKH 120
121 EASGKVNEID PPLSA
|
| Detection Method: | |
| Confidence: | 18.69897 |
| Match: | 1h88C |
| Description: | c-Myb, DNA-binding domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [204-444] |
1 11 21 31 41 51
| | | | | |
1 LAGVKKKGNV PQAKDIIKLE AAKQQSDRSV GEKKLRLPGE KVPLVTELYG YNLKREEFEI 60
61 EHDNDAEQLL ADMEFKDSDT DAEREQKLQV LRIYSKRLDE RKRRKEFVLE RNLLYPDQYE 120
121 MSLSAEERKI YKSCKVFARF QSKEEHKELI KKVIEEHQIL RRIEDLQEAR TAGCRTTSDA 180
181 NRFIEEKRKK EAEESMLLRL NHGAPGSIAG KTLKSPRGLP RNLHPFGSDS LPKVTPPRIY 240
241 S
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [445-527] |
1 11 21 31 41 51
| | | | | |
1 GLDTWDVDGL LGADLLSETE KKMCNETRIL PVHYLKMLDI LTREIKKGQI KKKSDAYSFF 60
61 KVEPSKVDRV YDMLVHKGIG DST
|
| Detection Method: | |
| Confidence: | 21.30103 |
| Match: | 2cujA |
| Description: | Solution structure of SWIRM domain of mouse transcriptional adaptor 2-like |
Matching Structure (courtesy of the PDB): |
|