| Protein: | ltd-1 |
| Organism: | Caenorhabditis elegans |
| Length: | 723 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for ltd-1.
| Description | E-value | Query Range |
Subject Range |
|
|
541.0 | [0..1] | [723..1] |
|
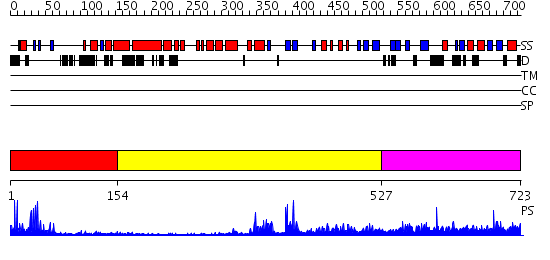
Region A: Residues: [1-153] |
1 11 21 31 41 51
| | | | | |
1 MNSKQHCNRC GKQVYPTDKV GPLKDSTFFH QGCFKCYICG TRLALKTYCN NRNDINDKEV 60
61 YCSNHVPIAG PHDLPMASTN GSGKNLENNN HVKNGNWIDA GLSDMKIAHA MKATQVARPY 120
121 PKISHEGAKY VVDYDTQTRL ELLHRKDEDD LYE
|
| Detection Method: | |
| Confidence: | 18.69897 |
| Match: | 1b8tA |
| Description: | Cysteine-rich (intestinal) protein, CRP, CRIP |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| binding | 0.270879137859077 | bayes_pls_golite062009 |
|
Region A: Residues: [154-526] |
1 11 21 31 41 51
| | | | | |
1 SFQDKRVREA EEFEKENTEE WEKALAEFAK KYEKGQSNMK KDDLIRQLTI KREKKLETLH 60
61 TKRKERERHQ TAELVDRQAK EMLELFKASR SEYSNLQYPS TPPPPVPPSC SKREIYTTTD 120
121 YFSSIDEVAI HCARNEVASF TDLIRTLSSG ARSDVDVARA IYRWITIKNL NTMIFDDSIQ 180
181 NDTPMGLLRG IKYGTESYHV LFKRLCSYAG LHCVVIKGFS KSAGYQPGYS FDDHRFRNTW 240
241 NAVFLDGSWR FVQCNWGARH LVNAKDGSHE AKTDGNLRYE YDDHYFMTDS EEFIYEFFPS 300
301 DHAWQLLPRP LSLLQFERIP FVRSLFFKYN LSFIDNKLES TVYTDKSGAA SISIRLPPKG 360
361 DSLIFHYNLK FFD
|
| Detection Method: | |
| Confidence: | 11.522879 |
| Match: | 1g0dA |
| Description: | Transglutaminase N-terminal domain; Transglutaminase, two C-terminal domains; Transglutaminase catalytic domain |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| catalytic activity | 0.529663942126259 | bayes_pls_golite062009 |
| hydrolase activity | 0.16837900182603 | bayes_pls_golite062009 |
|
Region A: Residues: [527-723] |
1 11 21 31 41 51
| | | | | |
1 SEENTISGMS LKRFVMQSVT EDVVTFRVHA PSTRPLLLDI FANSVSSGAY LTGQPIKFKS 60
61 VCKFKVVCES LQVIMVPLPE CASGEWGPAK ATRLFGLLPI SHPDAIINTG RYVEIRFRMT 120
121 RPLSEFVASL HRNRTDDRAL QACTRSALKG DMVYIQIEFP GEGQYGLDIY TRQDDQLING 180
181 KQLLTHCCKY LIHSRNC
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.