| Protein: | CE24996 |
| Organism: | Caenorhabditis elegans |
| Length: | 742 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CE24996.
| Description | E-value | Query Range |
Subject Range |
|
|
937.0 | [0..2] | [742..1] |
|
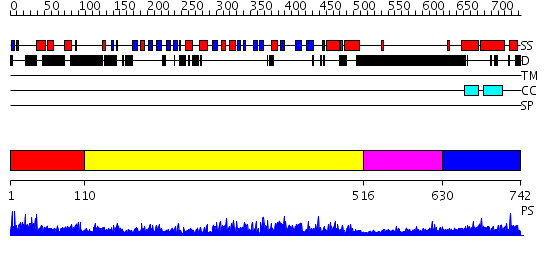
Region A: Residues: [1-109] |
1 11 21 31 41 51
| | | | | |
1 MDWIYSWKDS IFYGMCSCSG SPSYHEKDVP HPHDRLDMPL QLKAYRRNSL NAEGYYRDLE 60
61 RMHERGLFTT GINYNAEKSE DFLNMIERMQ SNRLDDQRCE MPERTHNPT
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [110-515] |
1 11 21 31 41 51
| | | | | |
1 SGHQNEQTHQ KTNGSAVHNQ LTRNIMNEVL TKVGPYPQIV LPSNGFWMDG VNQQHHMDDQ 60
61 VNNMNVNSCA RFKLETDETS HCYRRHFFGR EHHDFFANDP IVGPLVLSVR TEVISSCDHF 120
121 RIILRTRKGT IHEIVSATAL ADRPSASRMA KLLCEEITTE QFSPVAFPGG SELIVQYDEH 180
181 VLTNTYKFGV IYQKGGQTTE EQLFGNPHGS PAFDEFLSMI GDSVQLNGFQ KYRGGLDTAH 240
241 NQTGHQSVFS EFKNREIMFH VSTMLPYTIG DAQQLQRKRH IGNDIVAIIF QEANTPFAPD 300
301 MIASNFLHAY VVVQPIDALT DRVRYRVSVA ARDDVPFFGP TLPTPSIFKR GQDFRNFLLT 360
361 KLINAENAAY KSSKFAKLAE RTRSSLLDGL HATLRERAEF YATPLL
|
| Detection Method: | |
| Confidence: | 129.0 |
| Match: | 1srqA |
| Description: | Crystal Structure of the Rap1GAP catalytic domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [516-629] |
1 11 21 31 41 51
| | | | | |
1 ESTSSGGESA ATTSSSSNSY GGGILSSVKK AFIGRSRSVS QEASHVPHRA ATINVTSRPK 60
61 KSISSTSSST SARTHSPIRD EEVVKPYRKE WEISSQESPD NEHDSDTGME SMSS
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [630-742] |
1 11 21 31 41 51
| | | | | |
1 TEMSGQTRAS SCTFCVDDFH VAANHQSSDA KRLETLCVDV TRLQNEKHDL LRQNVSCKTD 60
61 IKKLKDRQSV LSEELERAND EISRLRRMLK KPSNSDMAPV HQHFERSYSD VSV
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.