| Protein: | CE19598 |
| Organism: | Caenorhabditis elegans |
| Length: | 798 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CE19598.
| Description | E-value | Query Range |
Subject Range |
|
|
508.0 | [0..1] | [797..1] |
|
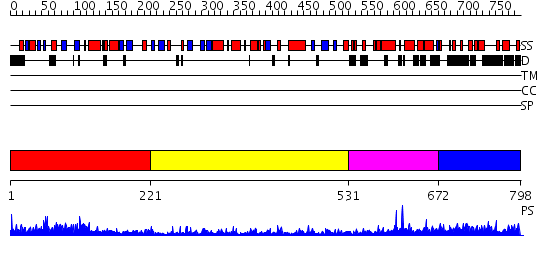
Region A: Residues: [1-220] |
1 11 21 31 41 51
| | | | | |
1 MLPSTSKSVE VNENSEEPIE LEENVIVVTG DEIQAEIAVV DGEEVIFADD DEYIEYDPLS 60
61 IANDRNAVYD IYQPHESENG TFMCKICMRT GKNTEYEDRS TFVAHRYKCH GSFNNNVMCP 120
121 LGDCREVFAS LYTLRRHLSQ QHELPIEIHL QSFVNIGEFE KFRHLVELAS GCRFMMHTKQ 180
181 PKYRRQVMHC SKSEHKLVLQ TQKHRLPRER MLKEGSACPS
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [221-530] |
1 11 21 31 41 51
| | | | | |
1 VISYRVESSS GEVHTFMQLY HIGHAPDTES QNSNADNARP MDIVFPIKPA CWANHPMQYV 60
61 QIDVHEMPTS IYGNKIYDNI LIVTCLKTRF LWAKPLFECT RTAIGRILNS IFNEYGVPEG 120
121 FSTSFSPTYI RDTIKSLESV YAVEIREVWN EPLPYNCLER WVLELAQNEL GTRNRWVEQL 180
181 QFLVMEYNQK PIPDRMETPF ERMFNRKAPN LYHNGDNQEI IHDKYISYHS ELRNEEEGVE 240
241 NRLNTSFEPG RKVFLRKGIT KPRRGNNTQY YFGYIGEVDP SNPYYPFKVH YTSSDSPWPS 300
301 ERNIYAWVSV
|
| Detection Method: | |
| Confidence: | 4.2 |
| Match: | 1k6yA |
| Description: | N-terminal Zn binding domain of HIV integrase; Retroviral integrase, catalytic domain |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| catalytic activity | 0.638749293464446 | bayes_pls_golite062009 |
| hydrolase activity | 0.094903118031094 | bayes_pls_golite062009 |
|
Region A: Residues: [531-671] |
1 11 21 31 41 51
| | | | | |
1 FDLLPTIHEI SEMSMTSKKV SIAGLLCSCM GIESSQKYDL TAMGDIARES SRCLLFRNCL 60
61 CTNQMSRFCC KLVGREHCRF HSVYPENDES YAKMDAALSS FIAYNKDSSK EAEKDLQDST 120
121 PIEQILNEVG RRRLESEITV E
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [672-798] |
1 11 21 31 41 51
| | | | | |
1 DPEDLAPPIL EPMEPTERHL DTEEEEEEPN QIPMASEHID IEGVDEEEIM EHSVNAISEE 60
61 ILFEYADDKR DDGPSTPKRG RRRKSPSESA GKKKKLSNND EFVESTVSRR SSARRTIRPK 120
121 NLDDYVE
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.