| Protein: | CSN7A_MOUSE |
| Organism: | Mus musculus |
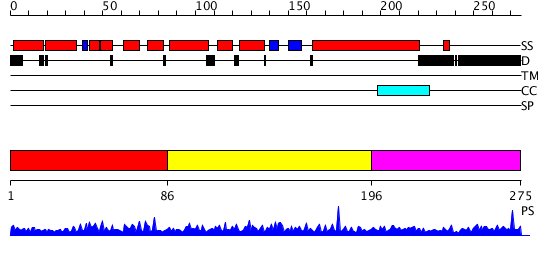
| Length: | 275 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CSN7A_MOUSE.
| Description | E-value | Query Range |
Subject Range |
|
|
290.0 | [0..1] | [275..1] |
|
|
288.0 | [0..1] | [275..1] |
|
|
287.0 | [0..1] | [275..1] |
|
|
287.0 | [0..1] | [275..1] |
|
|
281.0 | [0..1] | [267..244] |
|
|
279.0 | [0..1] | [267..59] |
|
|
276.0 | [0..1] | [264..1] |
|
Region A: Residues: [1-85] |
1 11 21 31 41 51
| | | | | |
1 MSAEVKVTGQ NQEQFLLLAK SAKGAALATL IHQVLEAPGV YVFGELLDMP NVRELAESDF 60
61 ASTFRLLTVF AYGTYADYLA EARNL
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [86-195] |
1 11 21 31 41 51
| | | | | |
1 PPLTDAQKNK LRHLSVVTLA AKVKCIPYAV LLEALALRNV RQLEDLVIEA VYADVLRGSL 60
61 DQRNQRLEVD YSIGRDIQRQ DLSAIAQTLQ EWCVGCEVVL SGIEEQVSRA
|
| Detection Method: | |
| Confidence: | 2.95 |
| Match: | 1ufmA |
| Description: | Solution structure of the PCI domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [196-275] |
1 11 21 31 41 51
| | | | | |
1 NQHKEQQLGL KQQIESEVAN LKKTIKVTTA AAAAATSQDP EQHLTELREP ASGTNQRQPS 60
61 KKASKGKGLR GSAKIWSKSN
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.