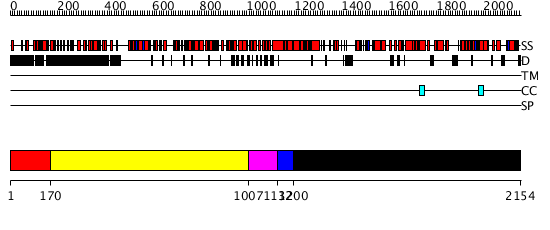
| Protein: | TEB_ARATH |
| Organism: | Arabidopsis thaliana |
| Length: | 2154 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for TEB_ARATH.
|
Region A: Residues: [1-169] |
1 11 21 31 41 51
| | | | | |
1 MDSDSSKSRI DQFYVSKKRK HQSPNLKSGR NEKNVKVTGE RSPGDKGTLD SYLKASLDDK 60
61 STTNSGLQAR QEAFTRKLDL EVSASSVGQN IHPCLPKPVS FATFKECLGQ NGSQDLHKEG 120
121 VAAETHATDG LLCANQKDNS ELRDFATSFL SLYCSGVQSV VGSPPHQKE
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [170-1006] |
1 11 21 31 41 51
| | | | | |
1 NELKRRSSSS SLAQDIQISH KRRCESENIP SLDDLTNPLG SKPESLARNG NNRDKPVSDP 60
61 TKKMPSNESV EIPMGLRKCS KAPESSAHLT EFHTPGSAIK SCPVGTPKSG CGSSMFSPGE 120
121 AFWNEAIQVA DGLTIPIENF GSVEAKVRDQ HVTILSCSKK TDKCTEKLER SLDLDEIRVK 180
181 DKDAIGFSKV VEKHGRDFNK EVYQLPVKNL ELLFQDKNIN GGIQERCASF DQNNITLGSS 240
241 RISESAFVGN KGCENLDIAN NAQADKGLIG KMYPEPEGKK VLLCEENRGV RSVSMISNMR 300
301 KPVGSSESEE SHTPSSSHRN YDGLSLSTWL PSEVCSVYNK KGISKLYPWQ VECLQVDGVL 360
361 QKRNLVYCAS TSAGKSFVAE VLMLRRVIRT GKMALLVLPY VSICAEKAEH LEVLLEPLGK 420
421 HVRSYYGNQG GGTLPKDTSV AVCTIEKANS LINRLLEEGR LSELGIIVID ELHMVGDQHR 480
481 GYLLELMLTK LRYAAGEGSS ESSSGESSGT SSGKADPAHG LQIVGMSATM PNVGAVADWL 540
541 QAALYQTEFR PVPLEEYIKV GSTIYNKKME VVRTIPKAAD MGGKDPDHIV ELCNEVVQEG 600
601 NSVLIFCSSR KGCESTARHI SKLIKNVPVN VDGENSEFMD IRSAIDALRR SPSGVDPVLE 660
661 ETLPSGVAYH HAGLTVEERE IVETCYRKGL VRVLTATSTL AAGVNLPARR VIFRQPMIGR 720
721 DFIDGTRYKQ MSGRAGRTGI DTKGDSVLIC KPGELKRIMA LLNETCPPLQ SCLSEDKNGM 780
781 THAILEVVAG GIVQTAKDIH RYVRCTLLNS TKPFQDVVKS AQDSLRWLCH RKFLEWN
|
| Detection Method: | |
| Confidence: | 29.0 |
| Match: | 1gm5A |
| Description: | RecG, N-terminal domain; RecG "wedge" domain; RecG helicase domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [1007-1131] |
1 11 21 31 41 51
| | | | | |
1 EETKLYTTTP LGRGSFGSSL CPEESLIVLD DLLRAREGLV MASDLHLVYL VTPINVGVEP 60
61 NWELYYERFM ELSPLEQSVG NRVGVVEPFL MRMAHGATVR TLNRPQDVKK NLRGEYDSRH 120
121 GSTSM
|
| Detection Method: | |
| Confidence: | 70.39794 |
| Match: | 2p6rA |
| Description: | No description for 2p6rA was found. |
|
Region A: Residues: [1132-1199] |
1 11 21 31 41 51
| | | | | |
1 KMLSDEQMLR VCKRFFVALI LSKLVQEASV TEVCEAFKVA RGMVQALQEN AGRFSSMVSV 60
61 FCERLGWH
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [1200-2154] |
1 11 21 31 41 51
| | | | | |
1 DLEGLVAKFQ NRVSFGVRAE IVELTSIPYI KGSRARALYK AGLRTSQAIA EASIPEIVKA 60
61 LFESSAWAAE GTGQRRIHLG LAKKIKNGAR KIVLEKAEEA RAAAFSAFKS LGLDVNELSK 120
121 PLPLAPASSL NGQETTERDI SRGSVGPDGL QQSIEGHMEC ENFDMDNHRE KPSEVLGDAT 180
181 LGVSSEINLT SRLPNFRPIG TAVGTNGPSA VSILSSDTFP IPVYDNREIK PKDNVEQHLT 240
241 RNDHIPLSSN KDGTGEKGPV TAGNISGGFD SFLELWGSAG EFFFDLHYNK LQDLNSRISY 300
301 EIHGIAICWN CSPVYYVNLN KDLPNLECVE KQKLIEDAVI GKSEVLASHN MLDVIKSRWN 360
361 KISKIMGNVN TRKFTWNLKV QIQVLKSPAI SIQRCTRLNL PEGIRDELVD GSWLMMPPLH 420
421 TSHTIDMSIV IWILWPDEER HSNPNIDKEV KKRLSPEAAE AANRSGRWRN QIRRVAHNGC 480
481 CRRVAQTRAL CSALWKILVS EELLQALTTI EMPLVNVLAD MELWGIGIDI EGCLRARNIL 540
541 RDKLRSLEKK AFELAGMTFS LHNPADIANV LFGQLKLPIP ENQSKGKLHP STDKHCLDLL 600
601 RNEHPVVPII KEHRTLAKLL NCTLGSICSL AKLRLSTQRY TLHGRWLQTS TATGRLSIEE 660
661 PNLQSVEHEV EFKLDKNGRD VSSDADRYKI NARDFFVPTQ ENWLLLTADY SQIELRLMAH 720
721 FSRDSSLISK LSQPEGDVFT MIAAKWTGKA EDSVSPHDRD QTKRLIYGIL YGMGANRLAE 780
781 QLECTSDEAK EKIRSFKSSF PAVTSWLNET ISFCQEKGYI QTLKGRRRFL SKIKFGNAKE 840
841 KSKAQRQAVN SMCQGSAADI IKIAMINIYS AIAEDVDTAA SSSSSETRFH MLKGRCRILL 900
901 QVHDELVLEV DPSYVKLAAM LLQTSMENAV SLLVPLHVKL KVGKTWGSLE PFQTD
|
| Detection Method: | |
| Confidence: | 1000.0 |
| Match: | 1bgxT |
| Description: | 5' to 3' exonuclease domain of DNA polymerase Taq; Exonuclease domain of prokaryotic DNA polymerase; DNA polymerase I (Klenow fragment) |
Matching Structure (courtesy of the PDB): |
|