| Protein: | MSH1_ARATH |
| Organism: | Arabidopsis thaliana |
| Length: | 1118 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for MSH1_ARATH.
|
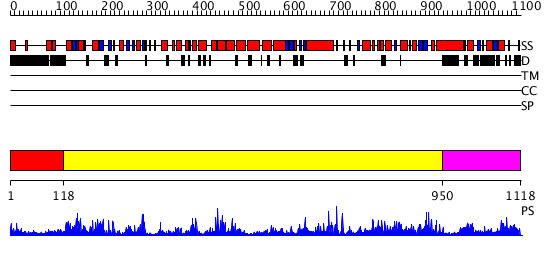
Region A: Residues: [1-117] |
1 11 21 31 41 51
| | | | | |
1 MHWIATRNAV VSFPKWRFFF RSSYRTYSSL KPSSPILLNR RYSEGISCLR DGKSLKRITT 60
61 ASKKVKTSSD VLTDKDLSHL VWWKERLQTC KKPSTLQLIE RLMYTNLLGL DPSLRNG
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [118-949] |
1 11 21 31 41 51
| | | | | |
1 SLKDGNLNWE MLQFKSRFPR EVLLCRVGEF YEAIGIDACI LVEYAGLNPF GGLRSDSIPK 60
61 AGCPIMNLRQ TLDDLTRNGY SVCIVEEVQG PTPARSRKGR FISGHAHPGS PYVYGLVGVD 120
121 HDLDFPDPMP VVGISRSARG YCMISIFETM KAYSLDDGLT EEALVTKLRT RRCHHLFLHA 180
181 SLRHNASGTC RWGEFGEGGL LWGECSSRNF EWFEGDTLSE LLSRVKDVYG LDDEVSFRNV 240
241 NVPSKNRPRP LHLGTATQIG ALPTEGIPCL LKVLLPSTCS GLPSLYVRDL LLNPPAYDIA 300
301 LKIQETCKLM STVTCSIPEF TCVSSAKLVK LLEQREANYI EFCRIKNVLD DVLHMHRHAE 360
361 LVEILKLLMD PTWVATGLKI DFDTFVNECH WASDTIGEMI SLDENESHQN VSKCDNVPNE 420
421 FFYDMESSWR GRVKGIHIEE EITQVEKSAE ALSLAVAEDF HPIISRIKAT TASLGGPKGE 480
481 IAYAREHESV WFKGKRFTPS IWAGTAGEDQ IKQLKPALDS KGKKVGEEWF TTPKVEIALV 540
541 RYHEASENAK ARVLELLREL SVKLQTKINV LVFASMLLVI SKALFSHACE GRRRKWVFPT 600
601 LVGFSLDEGA KPLDGASRMK LTGLSPYWFD VSSGTAVHNT VDMQSLFLLT GPNGGGKSSL 660
661 LRSICAAALL GISGLMVPAE SACIPHFDSI MLHMKSYDSP VDGKSSFQVE MSEIRSIVSQ 720
721 ATSRSLVLID EICRGTETAK GTCIAGSVVE SLDTSGCLGI VSTHLHGIFS LPLTAKNITY 780
781 KAMGAENVEG QTKPTWKLTD GVCRESLAFE TAKREGVPES VIQRAEALYL SV
|
| Detection Method: | |
| Confidence: | 1000.0 |
| Match: | 1e3mA |
| Description: | DNA repair protein MutS, domain III; DNA repair protein MutS, the C-terminal domain; DNA repair protein MutS, domain II; DNA repair protein MutS, domain I |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [950-1118] |
1 11 21 31 41 51
| | | | | |
1 YAKDASAEVV KPDQIITSSN NDQQIQKPVS SERSLEKDLA KAIVKICGKK MIEPEAIECL 60
61 SIGARELPPP STVGSSCVYV MRRPDKRLYI GQTDDLEGRI RAHRAKEGLQ GSSFLYLMVQ 120
121 GKSMACQLET LLINQLHEQG YSLANLADGK HRNFGTSSSL STSDVVSIL
|
| Detection Method: | |
| Confidence: | 5.0 |
| Match: | 1qvrA |
| Description: | Crystal Structure Analysis of ClpB |
Matching Structure (courtesy of the PDB): |
|