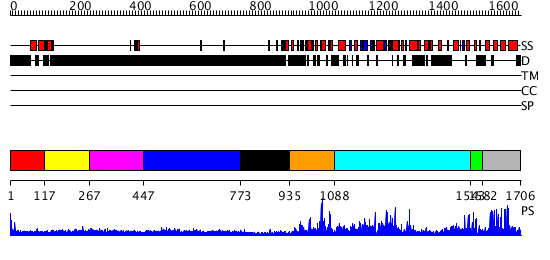
| Protein: | HAC12_ARATH |
| Organism: | Arabidopsis thaliana |
| Length: | 1706 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for HAC12_ARATH.
|
Region A: Residues: [1-116] |
1 11 21 31 41 51
| | | | | |
1 MNVQAHMSGQ RSGQVPNQGT VPQNNGNSQM QNLVGSNGAA TAVTGAGAAT GSGTGVRPSR 60
61 NIVGAMDHDI MKLRQYMQTL VFNMLQQRQP SPADAASKAK YMDVARRLEE GLFKMA
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [117-266] |
1 11 21 31 41 51
| | | | | |
1 VTKEDYMNRS TLESRITSLI KGRQINNYNQ RHANSSSVGT MIPTPGLSQT AGNPNLMVTS 60
61 SVDATIVGNT NITSTALNTG NPLIAGGMHG GNMSNGYQHS SRNFSLGSGG SMTSMGAQRS 120
121 TAQMIPTPGF VNSVTNNNSG GFSAEPTIVP
|
| Detection Method: | |
| Confidence: | 7.0 |
| Match: | 1m2vB |
| Description: | Sec24 |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [267-446] |
1 11 21 31 41 51
| | | | | |
1 QSQQQQQRQH TGGQNSHMLS NHMAAGVRPD MQSKPSGAAN SSVNGDVGAN EKIVDSGSSY 60
61 TNASKKLQQG NFSLLSFCPD DLISGQHIES TFHISGEGYS TTNPDPFDGA ITSAGTGTKA 120
121 HNINTASFQP VSRVNSSLSH QQQFQQPPNR FQQQPNQIQQ QQQQFLNQRK LKQQTPQQHR 180
181
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [447-772] |
1 11 21 31 41 51
| | | | | |
1 LISNDGLGKT QVDSDMVTKV KCEPGMENKS QAPQSQASER FQLSQLQNQY QNSGEDCQAD 60
61 AQLLPVESQS DICTSLPQNS QQIQQMMHPQ NIGSDSSNSF SNLAVGVKSE SSPQGQWPSK 120
121 SQENTLMSNA ISSGKHIQED FRQRITGMDE AQPNNLTEGS VIGQNHTSTI SESHNLQNSI 180
181 GTTCRYGNVS HDPKFKNQQR WLLFLRHARS CKPPGGRCQD QNCVTVQKLW SHMDNCADPQ 240
241 CLYPRCRHTK ALIGHYKNCK DPRCPVCVPV KTYQQQANVR ALARLKNESS AVGSVNRSVV 300
301 SNDSLSANAG AVSGTPRCAD TLDNLQ
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [773-934] |
1 11 21 31 41 51
| | | | | |
1 PSLKRLKVEQ SFQPVVPKTE SCKSSIVSTT EADLSQDAER KDHRPLKSET MEVKVEIPDN 60
61 SVQAGFGIKE TKSEPFENVP KPKPVSEPGK HGLSGDSPKQ ENIKMKKEPG WPKKEPGCPK 120
121 KEELVESPEL TSKSRKPKIK GVSLTELFTP EQVREHIRGL RQ
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [935-1087] |
1 11 21 31 41 51
| | | | | |
1 WVGQSKAKAE KNQAMENSMS ENSCQLCAVE KLTFEPPPIY CTPCGARIKR NAMYYTVGGG 60
61 ETRHYFCIPC YNESRGDTIL AEGTSMPKAK LEKKKNDEEI EESWVQCDKC QAWQHQICAL 120
121 FNGRRNDGGQ AEYTCPYCYV IDVEQNERKP LLQ
|
| Detection Method: | |
| Confidence: | 31.69897 |
| Match: | 2i13A |
| Description: | No description for 2i13A was found. |
|
Region A: Residues: [1088-1542] |
1 11 21 31 41 51
| | | | | |
1 SAVLGAKDLP RTILSDHIEQ RLFKRLKQER TERARVQGTS YDEIPTVESL VVRVVSSVDK 60
61 KLEVKSRFLE IFREDNFPTE FPYKSKVVLL FQKIEGVEVC LFGMYVQEFG SECSNPNQRR 120
121 VYLSYLDSVK YFRPDIKSAN GEALRTFVYH EILIGYLEYC KLRGFTSCYI WACPPLKGED 180
181 YILYCHPEIQ KTPKSDKLRE WYLAMLRKAA KEGIVAETTN LYDHFFLQTG ECRAKVTAAR 240
241 LPYFDGDYWP GAAEDIISQM SQEDDGRKGN KKGILKKPIT KRALKASGQS DFSGNASKDL 300
301 LLMHKLGETI HPMKEDFIMV HLQHSCTHCC TLMVTGNRWV CSQCKDFQLC DGCYEAEQKR 360
361 EDRERHPVNQ KDKHNIFPVE IADIPTDTKD RDEILESEFF DTRQAFLSLC QGNHYQYDTL 420
421 RRAKHSSMMV LYHLHNPTAP AFVTTCNVCH LDIES
|
| Detection Method: | |
| Confidence: | 136.0 |
| Match: | 3biyA |
| Description: | No description for 3biyA was found. |
|
Region A: Residues: [1543-1581] |
1 11 21 31 41 51
| | | | | |
1 GLGWRCEVCP DYDVCNACYK KEGCINHPHK LTTHPSLAD
|
| Detection Method: | |
| Confidence: | 17.0 |
| Match: | 1totA |
| Description: | ZZ Domain of CBP- a Novel Fold for a Protein Interaction Module |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [1582-1706] |
1 11 21 31 41 51
| | | | | |
1 QNAQNKEARQ LRVLQLRKML DLLVHASQCR SPVCLYPNCR KVKGLFRHGL RCKVRASGGC 60
61 VLCKKMWYLL QLHARACKES ECDVPRCGDL KEHLRRLQQQ SDSRRRAAVM EMMRQRAAEV 120
121 AGTSG
|
| Detection Method: | |
| Confidence: | 27.522879 |
| Match: | 1f81A |
| Description: | CREB-binding transcriptional adaptor protein CBP (p300) |
Matching Structure (courtesy of the PDB): |
|