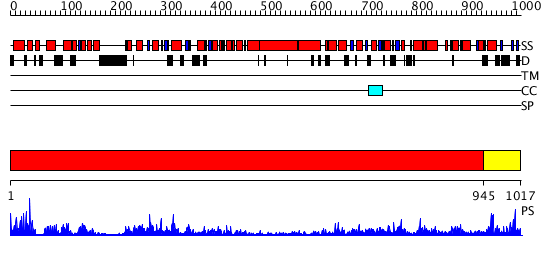
Region A:
Residues: [1-944]
|
1 11 21 31 41 51
| | | | | |
1 MRTGAYTVHQ TLTPEAASVL KQSLTLARRR GHSQVTPLHV ASTLLTSSRS NLFRRACLKS 60
61 NPFTALGRQM AHPSLHCRAL ELCFNVSLNR LPTNPNPLFQ TQPSLSNALV AALKRAQAHQ 120
121 RRGCVEQQQS QQNQPFLAVK VELEQLVVSI LDDPSVSRVM REAGLSSVSV KSNIEDDSSV 180
181 VSPVFYGSSS SVGVFSSPCS PSSSENNQGG GTLSPNPSKI WHAHLTNHHS FEQNPFFHFP 240
241 KGKTFTPDQA FPVREDANPV IEVLLGKKNN KKRNTVIVGD SVSLTEGVVA KLMGRIERGE 300
301 VPDDLKQTHF IKFQFSQVGL NFMKKEDIEG QVRELKRKID SFTSWGGKGV IVCLGDLDWA 360
361 VWGGGNSASS SNYSAADHLV EEIGRLVYDY SNTGAKVWLL GTASYQTYMR CQMKQPPLDV 420
421 HWALQAVSIP SGGLSLTLHA SSSEMASQVM EMKPFRVKEE EEGAREEEEE DKLNFCGECA 480
481 FNYEKEAKAF ISAQHKILPP WLQPHGDNNN INQKDELSGL RKKWNRFCQA LHHKKPSMTA 540
541 WRAEQSSSVL PGSLMDSSLK QNSRASSSVA KFRRQNSCTI EFSFGSNRQE GLKKTDELSL 600
601 DGFKSNNDEG VKTKITLALG HSPFPSDSEN SEEEEPEKAI KMSKLLEKLH ENIPWQKDVL 660
661 PSIVEAMEES VKRSKRKDAW MLVSGNDVTA KRRLAITLTT SLFGSHENML KINLRTSKAS 720
721 EACEELKNAL KKKEEVVILI ERVDLADAQF MNILVDRFEA GDLDGFQGKK SQIIFLLTRE 780
781 DDECVENEHF VIPMVLNCNK SGSGLVNNKR KPEYDAAPTM IKKKNPRIEE DDDESNVACD 840
841 ISNIKKEFSR QLKFESNALD LNLRVDADED EEEEAKPATE ISSGFEERFL DSIQNRFDFT 900
901 VLSDEDITKF FVTKIKDSCE EILGQREERF GFTVDAELIE KFYK
[Run NCBI BLAST on this sequence.]
|