| Protein: | CLCA_ARATH |
| Organism: | Arabidopsis thaliana |
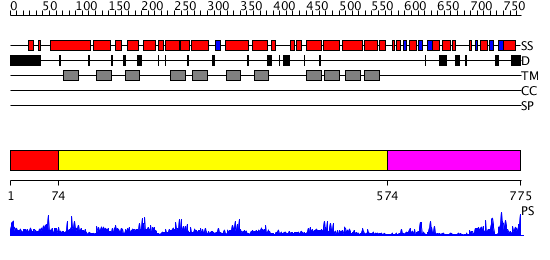
| Length: | 775 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CLCA_ARATH.
| Description | E-value | Query Range |
Subject Range |
|
|
526.0 | [0..1] | [775..1] |
|
|
492.0 | [0..8] | [772..13] |
|
|
481.0 | [0..9] | [773..13] |
|
|
454.0 | [0..16] | [766..50] |
|
|
442.0 | [0..14] | [770..1] |
|
Region A: Residues: [1-73] |
1 11 21 31 41 51
| | | | | |
1 MDEDGNLQIS NSNYNGEEEG EDPENNTLNQ PLLKRHRTLS STPLALVGAK VSHIESLDYE 60
61 INENDLFKHD WRS
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [74-573] |
1 11 21 31 41 51
| | | | | |
1 RSKAQVFQYI FLKWTLACLV GLFTGLIATL INLAVENIAG YKLLAVGYYI AQDRFWTGLM 60
61 VFTGANLGLT LVATVLVVYF APTAAGPGIP EIKAYLNGID TPNMFGFTTM MVKIVGSIGA 120
121 VAAGLDLGKE GPLVHIGSCI ASLLGQGGPD NHRIKWRWLR YFNNDRDRRD LITCGSASGV 180
181 CAAFRSPVGG VLFALEEVAT WWRSALLWRT FFSTAVVVVV LRAFIEICNS GKCGLFGSGG 240
241 LIMFDVSHVE VRYHAADIIP VTLIGVFGGI LGSLYNHLLH KVLRLYNLIN QKGKIHKVLL 300
301 SLGVSLFTSV CLFGLPFLAE CKPCDPSIDE ICPTNGRSGN FKQFNCPNGY YNDLSTLLLT 360
361 TNDDAVRNIF SSNTPNEFGM VSLWIFFGLY CILGLITFGI ATPSGLFLPI ILMGSAYGRM 420
421 LGTAMGSYTN IDQGLYAVLG AASLMAGSMR MTVSLCVIFL ELTNNLLLLP ITMFVLLIAK 480
481 TVGDSFNLSI YEIILHLKGL
|
| Detection Method: | |
| Confidence: | 57.69897 |
| Match: | 1kplA |
| Description: | Clc chloride channel |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [574-775] |
1 11 21 31 41 51
| | | | | |
1 PFLEANPEPW MRNLTVGELN DAKPPVVTLN GVEKVANIVD VLRNTTHNAF PVLDGADQNT 60
61 GTELHGLILR AHLVKVLKKR WFLNEKRRTE EWEVREKFTP VELAEREDNF DDVAITSSEM 120
121 QLYVDLHPLT NTTPYTVVQS MSVAKALVLF RSVGLRHLLV VPKIQASGMS PVIGILTRQD 180
181 LRAYNILQAF PHLDKHKSGK AR
|
| Detection Method: | |
| Confidence: | 18.0 |
| Match: | 1vrdA |
| Description: | Crystal structure of Inosine-5'-monophosphate dehydrogenase (TM1347) from THERMOTOGA MARITIMA at 2.18 A resolution |
Matching Structure (courtesy of the PDB): |
|