| Protein: | CE01358 |
| Organism: | Caenorhabditis elegans |
| Length: | 558 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CE01358.
| Description | E-value | Query Range |
Subject Range |
|
|
330.0 | [0..1] | [536..789] |
|
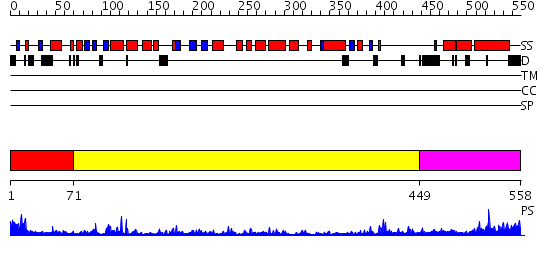
Region A: Residues: [1-70] |
1 11 21 31 41 51
| | | | | |
1 MVVEGYEEIA VDDDMNDMRE MVANDEDDSI HYEAHDGSEY GGMPIDQYQD IVMFKTTDQV 60
61 PASVSSRLDR
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [71-448] |
1 11 21 31 41 51
| | | | | |
1 SAPSHWRARC KCFSMADDRE TLLYYNPEKS ANTIPKVVVK KGEVQKVLER IHELIGHLGQ 60
61 KRTQMVVLRK LYWRSVRQDV KTFIASCDFC TAKKIQGRKI TKAPVDITSE HFDISVLVRD 120
121 SSSGNDRFEF QLVGYNEDEV REASFTRMTS YTFKETEHAF RSRYSNHQQT GPPTFRRQPY 180
181 VKKHKNQSVG YLLPFHQRSR ATEPEFIEVF GRDMFTHHPD MMYETVPEMD DGMMRSREEV 240
241 KRKDEELPNA HPVTVGGAVL NSNNFKTEDE GNLAVSSRSQ ESTSSASPQK MNHEQQRYSQ 300
301 KRHLEMRTGR TTRDMRDYES SGRQLSPTPT TTAGLLKKRR RELPSIRGMA NRFSLAIGDS 360
361 DRIDNTEVNR SNPHLIEY
|
| Detection Method: | |
| Confidence: | 4.53 |
| Match: | 1k6yA |
| Description: | N-terminal Zn binding domain of HIV integrase; Retroviral integrase, catalytic domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [449-558] |
1 11 21 31 41 51
| | | | | |
1 PDPSSILRGD NAGLPPVIMA PSTNDEVCKL QIEALQRHIH LQKMQEKLLH EQYEASMRIP 60
61 ITRYIEQEEE VQEEQLEVEH HHVMENHHQV YEEVEEEVVP QNPRRHIRHQ
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.