| Protein: | CG4301-PA |
| Organism: | Drosophila melanogaster |
| Length: | 1342 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for CG4301-PA.
| Description | E-value | Query Range |
Subject Range |
|
|
782.0 | [0..107] | [1342..2] |
|
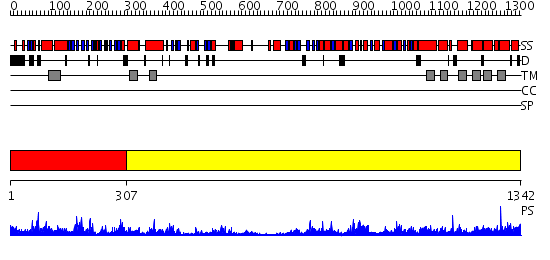
Region A: Residues: [1-306] |
1 11 21 31 41 51
| | | | | |
1 MNFFGHDHLS GFRRIDRLGA HRQTPWADQE SFHLKDAFLW NWHKGSRVST INDWLQIQIG 60
61 GPQDIKKKRP KGQNRIKSTK YTLITFLPQN LLEQFRRIAN FYFLVMTIIS LLIDSPVSPM 120
121 TSLLPLVFVI AVTAAKQGYE DILRYRTDNV VNSSPVTVIR DGKEAIIKSQ DVIPGELIVV 180
181 ERDCDVPCDL VLLRSTDPHG KCFITTANLD GESNLKTLMV PRDLPTVDLP EMHKLGIIEC 240
241 ESPTTDLYSF NGKIELKGGE GRVLPLSTEN VLLRGSRVKN TECVIGCAVY TGMISKLQLN 300
301 SRLTRN
|
| Detection Method: | |
| Confidence: | 59.045757 |
| Match: | 1mhsA |
| Description: | Proton ATPase |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [307-1342] |
1 11 21 31 41 51
| | | | | |
1 KNASSETYIN RFLIVILVAL IAIVTLLYFL KRYNELFVIP KLTYLGDATD SYSVKQFLQD 60
61 YLSFLILFNY LIPISLYVTI ELQRVIGSWF MEWDLELYEN ETDQPCVVNT SNLNEELGQI 120
121 NILFSDKTGT LTKNEMNFQQ CSINGNKFLF KKTRLEDEET KALLDINKFS ANQRVFFQAL 180
181 SICHTVQVAS GSLEQADAGT AKREPVTAIK SGPPEMYSIS DITEESHNAS QQSELNVGHT 240
241 IDNSVSAHPN GVNSTIISSD VNPLLVSDDG YGVERRKRPV VIKRSPNFAR SNRMNNGAAS 300
301 DLNINQTDPN TVTNGVEPTT NFRPISLQFR RSTSEKDLQQ SWEAPSGQAP GHRRAHSYGA 360
361 PNAYLTNPVT ASTPPAGVLF RSPSTTSRES YAAPTFTRQP TILVRAESQR RKNEIRDFIF 420
421 TLDYQASSPD EKALVEACAN LGMVYTGDDD ETLRVRIVPP HMDYKRPFAK PREETFQRLH 480
481 VLEFTSDRKR MSVIVRDTDG KKWIYTKGAE SYVFPLCANS SAELVTKTDA HISDFARLGL 540
541 RTLAIARRLI SEEEYQDFLV ELAQANSSLE NRKQLSEECY AKIESNLDLL GATAVEDALQ 600
601 DDVADTLVSL QAAGIKIWVL TGDKVETALN IALSCGHIPP DAKKYFIMEC KNREEMLLHL 660
661 NALDREIIFG IGQECALLID GKSLGVALAE ASSEFRDVAV KCTAVLCCRL SPLQKSEVVS 720
721 LIKSSNENYN TASIGDGAND VSMIQEAHVG IGIMGREGRQ AARCADFAFA KFCMLKRLLL 780
781 VHGHYHSVRL SLLVLYFFYK NIVFMGIMFL FQFHTLFSSS SVYDSLFLTL YNVIYTSLPI 840
841 LFIAISEKPY TEEKLMRTPQ LYKKNTDNKQ LHWPYFLMWV LFAIYHSVII FYFAFCFFYY 900
901 NNVLLNYGQT VAFSCFGTLL MWTVVVVVNL KLWLESMYLS FWYIFTIIIS ILGFVVTTVI 960
961 YNVINLDYDT DIYWAYNNLL ASLPVWLWII VTCVACLVPD YTIRMLQRAL NIKSFSIFPG1020
1021 KQRKLKMREK FESTYL
|
| Detection Method: | |
| Confidence: | 118.0 |
| Match: | 1iwoA |
| Description: | Calcium ATPase, transduction domain A; Calcium ATPase, catalytic domain P; Calcium ATPase; Calcium ATPase, transmembrane domain M |
Matching Structure (courtesy of the PDB): |
|