| Protein: | NOC4L |
| Organism: | Homo sapiens |
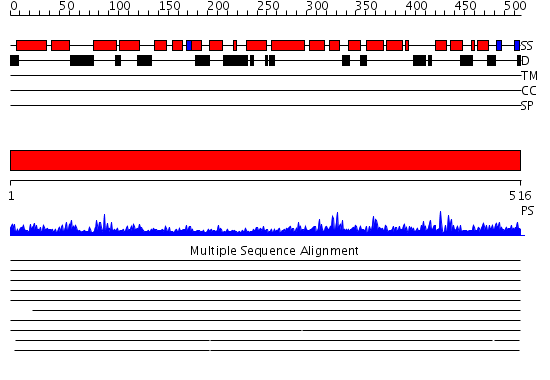
| Length: | 516 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for NOC4L.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..516] | [1..516] |
|
|
0.0 | [1..516] | [1..516] |
|
|
0.0 | [1..516] | [1..516] |
|
|
0.0 | [23..516] | [1..494] |
|
|
0.0 | [1..516] | [1..516] |
|
|
0.0 | [6..515] | [16..525] |
|
Region A: Residues: [1-516] |
1 11 21 31 41 51
| | | | | |
1 MEREPGAAGV RRALGRRLEA VLASRSEANA VFDILAVLQS EDQEEIQEAV RTCSRLFGAL 60
61 LERGELFVGQ LPSEEMVMTG SQGATRKYKV WMRHRYHSCC NRLGELLGHP SFQVKELALS 120
121 ALLKFVQLEG AHPLEKSKWE GNYLFPRELF KLVVGGLLSP EEDQSLLLSQ FREYLDYDDT 180
181 RYHTMQAAVD AVARVTGQHP EVPPAFWNNA FTLLSAVSLP RREPTVSSFY VKRAELWDTW 240
241 KVAHLKEHRR VFQAMWLSFL KHKLPLSLYK KVLLIVHDAI LPQLAQPTLM IDFLTRACDL 300
301 GGALSLLALN GLFILIHKHN LEYPDFYRKL YGLLDPSVFH VKYRARFFHL ADLFLSSSHL 360
361 PAYLVAAFAK RLARLALTAP PEALLMVLPF ICNLLRRHPA CRVLVHRPHG PELDADPYDP 420
421 GEEDPAQSRA LESSLWELQA LQRHYHPEVS KAASVINQAL SMPEVSIAPL LELTAYEIFE 480
481 RDLKKKGPEP VPLEFIPAQG LLGRPGELCA QHFTLS
|
| Detection Method: | |
| Confidence: | 1.12 |
| Match: | 1gw5B |
| Description: | Adaptin beta subunit N-terminal fragment |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| binding | 0.94245645040501 | bayes_pls_golite062009 |
| protein binding | 0.40342012399316 | bayes_pls_golite062009 |
| RNA binding | 0.355270528730177 | bayes_pls_golite062009 |