| Protein: | NCAPG |
| Organism: | Homo sapiens |
| Length: | 1015 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for NCAPG.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..1015] | [1..1017] |
|
|
0.0 | [1..1015] | [1..1015] |
|
|
0.0 | [1..1015] | [1..1024] |
|
|
0.0 | [1..1015] | [1..1003] |
|
|
0.0 | [1..1013] | [1..1039] |
|
|
0.0 | [1..1015] | [1..1004] |
|
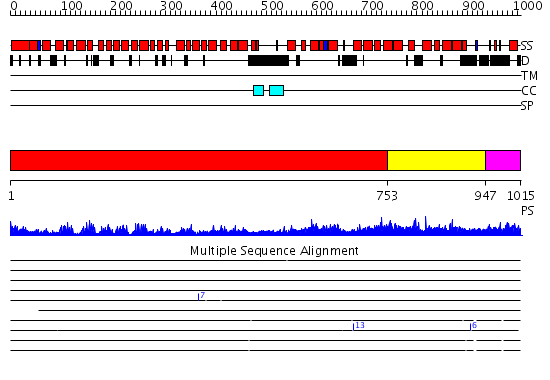
Region A: Residues: [1-752] |
1 11 21 31 41 51
| | | | | |
1 MGAERRLLSI KEAFRLAQQP HQNQAKLVVA LSRTYRTMDD KTVFHEEFIH YLKYVMVVYK 60
61 REPAVERVIE FAAKFVTSFH QSDMEDDEEE EDGGLLNYLF TFLLKSHEAN SNAVRFRVCL 120
121 LINKLLGSMP ENAQIDDDVF DKINKAMLIR LKDKIPNVRI QAVLALSRLQ DPKDDECPVV 180
181 NAYATLIEND SNPEVRRAVL SCIAPSAKTL PKIVGRTKDV KEAVRKLAYQ VLAEKVHMRA 240
241 MSIAQRVMLL QQGLNDRSDA VKQAMQKHLL QGWLRFSEGN ILELLHRLDV ENSSEVAVSV 300
301 LNALFSITPL SELVGLCKNN DGRKLIPVET LTPEIALYWC ALCEYLKSKG DEGEEFLEQI 360
361 LPEPVVYADY LLSYIQSIPV VNEEHRGDFS YIGNLMTKEF IGQQLILIIK SLDTSEEGGR 420
421 KKLLAVLQEI LILPTIPISL VSFLVERLLH IIIDDNKRTQ IVTEIISEIR APIVTVGVNN 480
481 DPADVRKKEL KMAEIKVKLI EAKEALENCI TLQDFNRASE LKEEIKALED ARINLLKETE 540
541 QLEIKEVHIE KNDAETLQKC LILCYELLKQ MSISTGLSAT MNGIIESLIL PGIISIHPVV 600
601 RNLAVLCLGC CGLQNQDFAR KHFVLLLQVL QIDDVTIKIS ALKAIFDQLM TFGIEPFKTK 660
661 KIKTLHCEGT EINSDDEQES KEVEETATAK NVLKLLSDFL DSEVSELRTG AAEGLAKLMF 720
721 SGLLVSSRIL SRLILLWYNP VTEEDVQLRH CL
|
| Detection Method: | |
| Confidence: | 26.69897 |
| Match: | 2h4mA |
| Description: | No description for 2h4mA was found. |
|
Region A: Residues: [753-946] |
1 11 21 31 41 51
| | | | | |
1 GVFFPVFAYA SRTNQECFEE AFLPTLQTLA NAPASSPLAE IDITNVAELL VDLTRPSGLN 60
61 PQAKTSQDYQ ALTVHDNLAM KICNEILTSP CSPEIRVYTK ALSSLELSSH LAKDLLVLLN 120
121 EILEQVKDRT CLRALEKIKI QLEKGNKEFG DQAEAAQDAT LTTTTFQNED EKNKEVYMTP 180
181 LRGVKATQAS KSTQ
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [947-1015] |
1 11 21 31 41 51
| | | | | |
1 LKTNRGQRKV TVSARTNRRC QTAEADSESD HEVPEPESEM KMRLPRRAKT AALEKSKLNL 60
61 AQFLNEDLS
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.