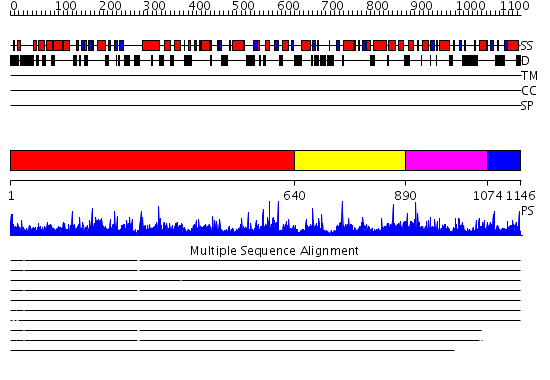
| Protein: | NOL6 |
| Organism: | Homo sapiens |
| Length: | 1146 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for NOL6.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..1146] | [12..1152] |
|
|
0.0 | [1..1146] | [1..1143] |
|
|
0.0 | [1..1146] | [1..1146] |
|
|
0.0 | [1..1146] | [1..1146] |
|
|
0.0 | [2..1146] | [145..1282] |
|
Region A: Residues: [1-639] |
1 11 21 31 41 51
| | | | | |
1 MGPAPAGEQL RGATGEPEVM EPALEGTGKE GKKASSRKRT LAEPPAKGLL QPVKLSRAEL 60
61 YKEPTNEELN RLRETEILFH SSLLRLQVEE LLKEVRLSEK KKDRIDAFLR EVNQRVVRVP 120
121 SVPETELTDQ AWLPAGVRVP LHQVPYAVKG CFRFLPPAQV TVVGSYLLGT CIRPDINVDV 180
181 ALTMPREILQ DKDGLNQRYF RKRALYLAHL AHHLAQDPLF GSVCFSYTNG CHLKPSLLLR 240
241 PRGKDERLVT VRLHPCPPPD FFRPCRLLPT KNNVRSAWYR GQSPAGDGSP EPPTPRYNTW 300
301 VLQDTVLESH LQLLSTILSS AQGLKDGVAL LKVWLRQREL DKGQGGFTGF LVSMLVVFLV 360
361 STRKIHTTMS GYQVLRSVLQ FLATTDLTVN GISLCLSSDP SLPALADFHQ AFSVVFLDSS 420
421 GHLNLCADVT ASTYHQVQHE ARLSMMLLDS RADDGFHLLL MTPKPMIRAF DHVLHLRPLS 480
481 RLQAACHRLK LWPELQDNGG DYVSAALGPL TTLLEQGLGA RLNLLAHSRP PVPEWDISQD 540
541 PPKHKDSGTL TLGLLLRPEG LTSVLELGPE ADQPEAAKFR QFWGSRSELR RFQDGAIREA 600
601 VVWEAASMSQ KRLIPHQVVT HLLALHADIP ETCVHYVGG
|
| Detection Method: | |
| Confidence: | 3.59 |
| Match: | 1q78A |
| Description: | Crystal structure of poly(A) polymerase in complex with 3'-dATP and magnesium chloride |
Matching Structure (courtesy of the PDB): |
|
| Term | Confidence | Notes |
| RNA binding | 0.210126436557659 | bayes_pls_golite062009 |
|
Region A: Residues: [640-889] |
1 11 21 31 41 51
| | | | | |
1 PLDALIQGLK ETSSTGEEAL VAAVRCYDDL SRLLWGLEGL PLTVSAVQGA HPVLRYTEVF 60
61 PPTPVRPAFS FYETLRERSS LLPRLDKPCP AYVEPMTVVC HLEGSGQWPQ DAEAVQRVRA 120
121 AFQLRLAELL TQQHGLQCRA TATHTDVLKD GFVFRIRVAY QREPQILKEV QSPEGMISLR 180
181 DTAASLRLER DTRQLPLLTS ALHGLQQQHP AFSGVARLAK RWVRAQLLGE GFADESLDLV 240
241 AAALFLHPEP
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [890-1073] |
1 11 21 31 41 51
| | | | | |
1 FTPPSSPQVG FLRFLFLVST FDWKNNPLFV NLNNELTVEE QVEIRSGFLA ARAQLPVMVI 60
61 VTPQDRKNSV WTQDGPSAQI LQQLVVLAAE ALPMLEKQLM DPRGPGDIRT VFRPPLDIYD 120
121 VLIRLSPRHI PRHRQAVDSP AASFCRGLLS QPGPSSLMPV LGYDPPQLYL TQLREAFGDL 180
181 ALFF
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [1074-1146] |
1 11 21 31 41 51
| | | | | |
1 YDQHGGEVIG VLWKPTSFQP QPFKASSTKG RMVMSRGGEL VMVPNVEAIL EDFAVLGEGL 60
61 VQTVEARSER WTV
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
| MCM Score |
GO Score |
GO Term |
SCOP Match |
SCOP Description | ||
| View | Download | 0.856 | 0.142 | condensed nuclear chromosome | d.19.1 | MHC antigen-recognition domain |