| Protein: | MAPKAP1 |
| Organism: | Homo sapiens |
| Length: | 522 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for MAPKAP1.
| Description | E-value | Query Range |
Subject Range |
|
|
895.0 | [0..1] | [522..1] |
|
|
894.0 | [0..1] | [522..1] |
|
|
893.0 | [0..1] | [522..1] |
|
|
892.0 | [0..1] | [522..1] |
|
|
890.0 | [0..1] | [522..1] |
|
|
883.0 | [0..1] | [522..1] |
|
|
860.0 | [0..1] | [522..1] |
|
|
838.0 | [0..1] | [520..1] |
|
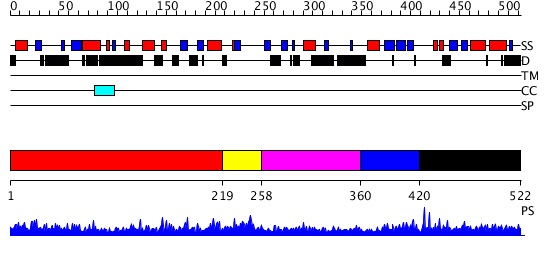
Region A: Residues: [1-218] |
1 11 21 31 41 51
| | | | | |
1 MAFLDNPTII LAHIRQSHVT SDDTGMCEMV LIDHDVDLEK IHPPSMPGDS GSEIQGSNGE 60
61 TQGYVYAQSV DITSSWDFGI RRRSNTAQRL ERLRKERQNQ IKCKNIQWKE RNSKQSAQEL 120
121 KSLFEKKSLK EKPPISGKQS ILSVRLEQCP LQLNNPFNEY SKFDGKGHVG TTATKKIDVY 180
181 LPLHSSQDRL LPMTVVTMAS ARVQDLIGLI CWQYTSEG
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [219-257] |
1 11 21 31 41 51
| | | | | |
1 REPKLNDNVS AYCLHIAEDD GEVDTDFPPL DSNEPIHKF
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [258-359] |
1 11 21 31 41 51
| | | | | |
1 GFSTLALVEK YSSPGLTSKE SLFVRINAAH GFSLIQVDNT KVTMKEILLK AVKRRKGSQK 60
61 VSGPQYRLEK QSEPNVAVDL DSTLESQSAW EFCLVRENSS RA
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [360-419] |
1 11 21 31 41 51
| | | | | |
1 DGVFEEDSQI DIATVQDMLS SHHYKSFKVS MIHRLRFTTD VQLGISGDKV EIDPVTNQKA 60
61
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
| MCM Score |
SCOP Match |
SCOP Description | ||
| View | Download | 0.814 | b.34.5 | Translation proteins SH3-like domain |
|
Region A: Residues: [420-522] |
1 11 21 31 41 51
| | | | | |
1 STKFWIKQKP ISIDSDLLCA CDLAEEKSPS HAIFKLTYLS NHDYKHLYFE SDAATVNEIV 60
61 LKVNYILESR ASTARADYFA QKQRKLNRRT SFSFQKEKKS GQQ
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
| MCM Score |
SCOP Match |
SCOP Description | ||
| View | Download | 0.828 | d.129.2 | Phosphoglucomutase, C-terminal domain |