| Protein: | ADCS_ARATH |
| Organism: | Arabidopsis thaliana |
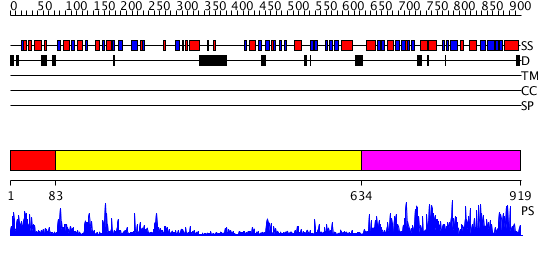
| Length: | 919 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for ADCS_ARATH.
|
Region A: Residues: [1-82] |
1 11 21 31 41 51
| | | | | |
1 MNMNFSFCST SSELSYPSEN VLRFSVASRL FSPKWKKSFI SLPCRSKTTR KVLASSRYVP 60
61 GKLEDLSVVK KSLPRREPVE KL
|
| Detection Method: | |
| Confidence: | 72.522879 |
| Match: | 1bxrB |
| Description: | Carbamoyl phosphate synthetase, small subunit N-terminal domain; Carbamoyl phosphate synthetase, small subunit C-terminal domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [83-633] |
1 11 21 31 41 51
| | | | | |
1 GFVRTLLIDN YDSYTFNIYQ ALSTINGVPP VVIRNDEWTW EEAYHYLYED VAFDNIVISP 60
61 GPGSPMCPAD IGICLRLLLE CRDIPILGVC LGHQALGYVH GAHVVHAPEP VHGRLSGIEH 120
121 DGNILFSDIP SGRNSDFKVV RYHSLIIDKE SLPKELVPIA WTIYDDTGSF SEKNSCVPVN 180
181 NTGSPLGNGS VIPVSEKLEN RSHWPSSHVN GKQDRHILMG IMHSSFPHYG LQFHPESIAT 240
241 TYGSQLFKNF KDITVNYWSR CKSTSLRRRN INDTANMQVP DATQLLKELS RTRCTGNGSS 300
301 YFGNPKSLFS AKTNGVDVFD MVDSSYPKPH TKLLRLKWKK HERLAHKVGG VRNIFMELFG 360
361 KNRGNDTFWL DTSSSDKARG RFSFMGGKGG SLWKQLTFSL SDQSEVTSKH AGHLLIEDSQ 420
421 SSTEKQFLEE GFLDFLRKEL SSISYDEKDF EELPFDFCGG YVGCIGYDIK VECGMPINRH 480
481 KSNAPDACFF FADNVVAIDH QLDDVYILSL YEEGTAETSF LNDTEEKLIS LMGLSTRKLE 540
541 DQTLPVIDSS Q
|
| Detection Method: | |
| Confidence: | 83.522879 |
| Match: | 1gpmA |
| Description: | GMP synthetase; GMP synthetase, central domain; GMP synthetase C-terminal dimerisation domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [634-919] |
1 11 21 31 41 51
| | | | | |
1 SKTSFVPDKS REQYINDVQS CMKYIKDGES YELCLTTQNR RKIGNADPLG LYLHLRERNP 60
61 APYAAFLNFS NANLSLCSSS PERFLKLDRN GMLEAKPIKG TIARGSTPEE DEFLKLQLKL 120
121 SEKNQAENLM IVDLLRNDLG RVCEPGSVHV PNLMDVESYT TVHTMVSTIR GLKKTDISPV 180
181 ECVRAAFPGG SMTGAPKLRS VEILDSLENC SRGLYSGSIG YFSYNGTFDL NIVIRTVIIH 240
241 EDEASIGAGG AIVALSSPED EFEEMILKTR APANAVMEFC SDQRRQ
|
| Detection Method: | |
| Confidence: | 127.0 |
| Match: | 1k0eA |
| Description: | P-aminobenzoate synthase component I |
Matching Structure (courtesy of the PDB): |
|