| Protein: | gi|23497111, gi|... |
| Organism: | Plasmodium falciparum 3D7 |
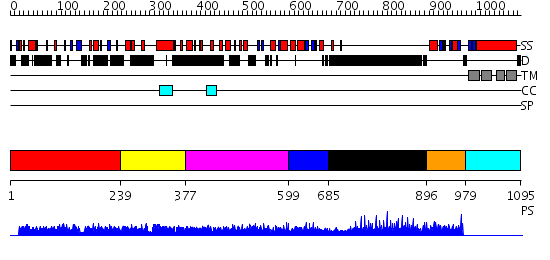
| Length: | 1095 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for gi|23497111, gi|....
| Description | E-value | Query Range |
Subject Range |
|
|
564.0 | [0..20] | [753..6] |
|
|
326.0 | [0..359] | [908..21] |
|
|
269.0 | [0..633] | [908..535] |
|
|
257.0 | [0..633] | [908..613] |
|
Region A: Residues: [1-238] |
1 11 21 31 41 51
| | | | | |
1 MVYSSNDDIP LDNRKDVIFN NAEKKNINFD KRRSCDYEYD EEENDKIIND ERIMSGGEEK 60
61 IYMSNIEGKE KNNLNDSNIL DKGRSRSSSN NVFKNIDKEN DRKKNDDIKD KEESNNIIEE 120
121 KDYYVMDKQM NISNTHKIDV ENEKIKNIHF SMNNEESNID DENKKENIFD IKKSISSYGN 180
181 IKNTSDSHKK GSVHKSETEK KDMNPIYDDN NYVWDKNDEN MKYGKNHINN NNNNNNVK
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [239-376] |
1 11 21 31 41 51
| | | | | |
1 NNDNNMYYEN DEKFYKREYI STDEHMKVDK EIVEIKDEKK EQKKPSILNK EENGKKNKDH 60
61 VIHNVEEAPG YEYSHNIIYH ELYVELLHVN KNLQNEIKNL KKIIEMQKIL IKSKEEVFLD 120
121 HLNEKNKMSN KKLMNHNY
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [377-598] |
1 11 21 31 41 51
| | | | | |
1 FLNFFNKKKK KSKEYKTSFK EEYEEEEDDE DIGYVVDRKK QTYFDVNKNY HGGKRELEEE 60
61 IHNVSEEHFD KKGSYLECEK IYNDDEDMFE YDMDVIYEKE ENKNNKYIKL PSIDNNDFSE 120
121 MTDRDIDSLY AYNNNNNNNN RNHNKNNNNS NNNSNIINIE KNDVYFFNDE KEESNYSRKY 180
181 EFEQSMLYNI EVEDESCNNS MTIQEITCLT FWYEEILPLV NN
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [599-684] |
1 11 21 31 41 51
| | | | | |
1 DKKKNLLINR MITNYMPNSI KGYFWEMCIK NKLNLTEYFV QILIKNTNFI QAYVYTNNRQ 60
61 YHNHVSRYFK SLIELRNNNL HIKEET
|
| Detection Method: | |
| Confidence: | 9.0 |
| Match: | 1mr5A |
| Description: | Trypanosoma sialidase, C-terminal domain; Trypanosoma sialidase |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [685-895] |
1 11 21 31 41 51
| | | | | |
1 IENDQDIEQK HDDNNIIFDS NKFHINDVHD KFDEQNDNIF YETQNMFDHK NKDPSDNKND 60
61 NPSDNKKDNP SDNKKDNPSD NKKDNPYDNK KDNPSDNKKD NPYDNKKDNP SDNKKDNPYD 120
121 NKKDNPSDNK KDNPYDNKKD NPYDNKKDNP YDNKKDNPYD NKKDNPYDNK KDNPYDNKKD 180
181 NPYDNKKDEN FCDDKNVIIY DNNKDKMSNM P
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [896-978] |
1 11 21 31 41 51
| | | | | |
1 NSNANINLLQ KFSVQKFFYQ ILIDLDRTMY IITKNKEYFA KYNIQTDNVL SSVNLSDMKK 60
61 KLNTLLQMYV LFKPELGYAK ANT
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [979-1095] |
1 11 21 31 41 51
| | | | | |
1 LKKKKNIYIY IYNRGVIYFF FLCPYVNIYL YIYVFFFFFF FFYSYVQGMS YIALVFLLYS 60
61 NLEKAFVHFA NFMVNLLSLV FLHTYVHVLT FFFHIKYILP FYFFIYPFMF TGKERYL
|
| Detection Method: | |
| Confidence: | 1.55 |
| Match: | 1zoyC |
| Description: | Crystal Structure of Mitochondrial Respiratory Complex II from porcine heart at 2.4 Angstroms |
Matching Structure (courtesy of the PDB): |
|