| Protein: | HESO1_ARATH |
| Organism: | Arabidopsis thaliana |
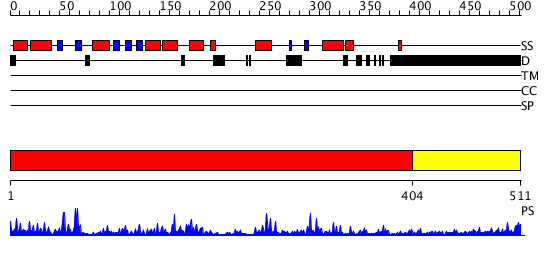
| Length: | 511 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for HESO1_ARATH.
| Description | E-value | Query Range |
Subject Range |
|
|
365.0 | [0..1] | [511..1] |
|
|
336.0 | [0..4] | [510..998] |
|
|
330.0 | [0..4] | [510..997] |
|
|
325.0 | [0..5] | [510..367] |
|
|
325.0 | [0..5] | [510..531] |
|
|
324.0 | [0..4] | [510..993] |
|
Region A: Residues: [1-403] |
1 11 21 31 41 51
| | | | | |
1 MSRNPFLDPT LQEILQVIKP TRADRDTRIT VIDQLRDVLQ SVECLRGATV QPFGSFVSNL 60
61 FTRWGDLDIS VDLFSGSSIL FTGKKQKQTL LGHLLRALRA SGLWYKLQFV IHARVPILKV 120
121 VSGHQRISCD ISIDNLDGLL KSRFLFWISE IDGRFRDLVL LVKEWAKAHN INDSKTGTFN 180
181 SYSLSLLVIF HFQTCVPAIL PPLRVIYPKS AVDDLTGVRK TAEESIAQVT AANIARFKSE 240
241 RAKSVNRSSL SELLVSFFAK FSDINVKAQE FGVCPFTGRW ETISSNTTWL PKTYSLFVED 300
301 PFEQPVNAAR SVSRRNLDRI AQVFQITSRR LVSECNRNSI IGILTGQHIQ ESLYRTISLP 360
361 SQHHANGMHN VRNLHGQARP QNQQMQQNWS QSYNTPNPPH WPP
|
| Detection Method: | |
| Confidence: | 57.30103 |
| Match: | 1f5aA |
| Description: | Poly(A) polymerase, middle domain; Poly(A) polymerase N-terminal, catalytic domain; Poly(A) polymerase, C-terminal domain |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [404-511] |
1 11 21 31 41 51
| | | | | |
1 LTQSRPQQNW TQNNPRNLQG QPPVQGQTWP VITQTQTQQK SPYKSGNRPL KNTSAGSSQN 60
61 QGHIGKPSGH MNGVNSARPA YTNGVNSARP PSKIPSQGGQ IWRPRHEQ
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.