| Protein: | CHR28_ARATH |
| Organism: | Arabidopsis thaliana |
| Length: | 981 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for CHR28_ARATH.
|
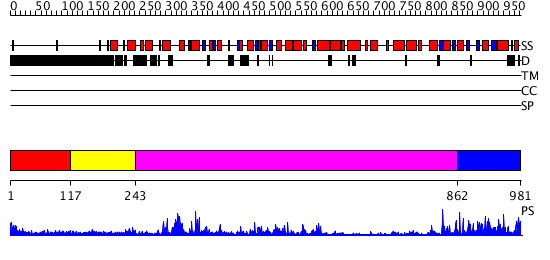
Region A: Residues: [1-116] |
1 11 21 31 41 51
| | | | | |
1 MDSAIDISSD SDVEIQETRT RPQHPPRIAE GSHRRDLSTL RPHFLSGSSS GANGHTKTGL 60
61 TNLDSRNGFE SKPLPRAEHH THIPGNGSIV TSRIPNISVG DYEKFSSQQA FKRTHP
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [117-242] |
1 11 21 31 41 51
| | | | | |
1 PTFSRPPFPP RPDIGTSNGN ASHFRGGAHD DLGMGRVTNG TRILPPSVAH GTSASPSHFN 60
61 GLSDPMHRNG IGEERNSEND ERLIYQAALQ ELNQPKSEVD LPAGLLSVPL MKHQKIALAW 120
121 MFQKET
|
| Detection Method: | |
| Confidence: | 4.39794 |
| Match: | 2b2uA |
| Description: | Tandem chromodomains of human CHD1 complexed with Histone H3 Tail containing trimethyllysine 4 and dimethylarginine 2 |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [243-861] |
1 11 21 31 41 51
| | | | | |
1 NSLHCMGGIL ADDQGLGKTV STIALILKQM HEAKLKSKNS GNQEAEALDL DADDESENAF 60
61 EKPESKASNG SGVNGDSGIK KAKGEEASTS TRKFNRKRPA AGTLIVCPAS VVRQWARELD 120
121 EKVTDEAKLS VLIYHGGNRT KDPIELAKYD VVMTTYAIVS NEVPKQPLVD DDENDEKNSE 180
181 KYGLASGFSI NKKRKNVVGT TKKSKKKKGN NNAGDSSDPD SGTLAKVGWF RVVLDEAQTI 240
241 KNHRTQVARA CCGLRAKRRW CLSGTPIQNT IDDLYSYFRF LKYDPYAVYK SFCHQIKGPI 300
301 SRNSLQGYKK LQAVLRAIML RRTKGTLLDG QPIINLPPKT INLSQVDFSV EERSFYVKLE 360
361 SDSRSQFKAY AAAGTLNQNY ANILLMLLRL RQACDHPQLV KRYNSDSVGK VSEEAVKKLP 420
421 KEDLVSLLSR LESSPICCVC HDPPEDPVVT LCGHIFCYQC VSDYITGDED TCPAPRCREQ 480
481 LAHDVVFSKS TLRSCVADDL GCSSSEDNSH DKSVFQNGEF SSSKIKAVLD ILQSLSNQGT 540
541 SNSTQNGQMA SSSQQPNDDD DDDDDDVTIV EKTSLKSTPS NGGPIKTIIF SQWTGMLDLV 600
601 ELSLIENSIE FRRLDGTMS
|
| Detection Method: | |
| Confidence: | 54.154902 |
| Match: | 1z3iX |
| Description: | Structure of the SWI2/SNF2 chromatin remodeling domain of eukaryotic Rad54 |
Matching Structure (courtesy of the PDB): |
|
|
Region A: Residues: [862-981] |
1 11 21 31 41 51
| | | | | |
1 LIARDRAVKE FSNDPDVKVM IMSLKAGNLG LNMIAACHVI LLDLWWNPTT EDQAIDRAHR 60
61 IGQTRPVTVT RITIKNTVED RILALQEEKR KMVASAFGED HGGSSATRLT VDDLKYLFMV 120
121
|
| Detection Method: | |
| Confidence: | 33.69897 |
| Match: | 1z5zA |
| Description: | Sulfolobus solfataricus SWI2/SNF2 ATPase C-terminal domain |
Matching Structure (courtesy of the PDB): |
|