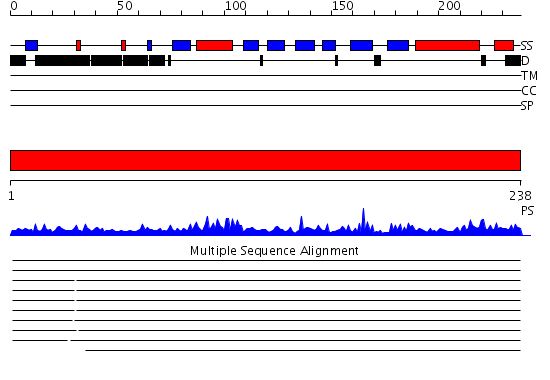
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for COQ10B.
| Description |
E-value |
Query
Range |
Subject
Range |
gi|114582370 - gi|114582370|ref|XP_001168795.1| PREDICTED: hypothetical protein isoform 1 [Pan troglodytes]
|
8.0E-78 |
[1..238] |
[1..238] |
CQ10B_PONPY - Protein COQ10 B, mitochondrial precursor - Pongo pygmaeus (Orangutan)
CQ10B_PONAB - Coenzyme Q-binding protein COQ10 homolog B, mitochondrial OS=Pongo abelii GN=COQ10B PE=2 SV=1
|
1.0E-77 |
[1..238] |
[1..238] |
gi|74223038, gi|... - gi|89337274|ref|NP_001034799.1| coenzyme Q10 homolog B isoform 1 [Mus musculus], gi|74223038|dbj|BAE...
|
8.0E-77 |
[1..238] |
[3..242] |
gi|34875875, gi|... - gi|57528275|ref|NP_001009671.1| coenzyme Q10 homolog B [Rattus norvegicus], gi|56972093|gb|AAH88273....
|
3.0E-76 |
[1..238] |
[3..242] |
gi|109100482 - gi|109100482|ref|XP_001088917.1| PREDICTED: similar to CG9410-PA, isoform A [Macaca mulatta]
|
3.0E-71 |
[1..238] |
[1..242] |
gi|94574086, gi|... - gi|94574086|gb|AAI16073.1| Coenzyme Q10 homolog B (S. cerevisiae) [Bos taurus], gi|115497098|ref|NP_...
|
1.0E-70 |
[1..238] |
[3..244] |
gi|74005472 - gi|74005472|ref|XP_536015.2| PREDICTED: similar to CG9410-PA, isoform A [Canis familiaris]
|
1.0E-68 |
[1..238] |
[110..351] |