| Protein: | C20orf4 |
| Organism: | Homo sapiens |
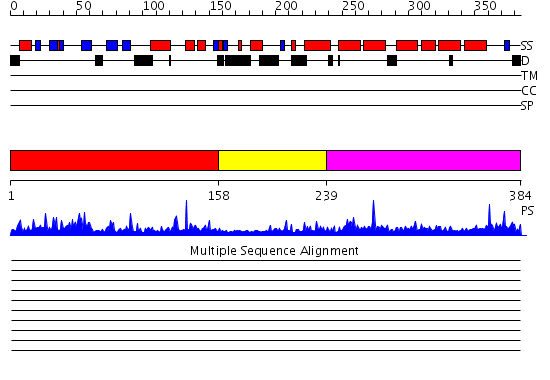
| Length: | 384 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for C20orf4.
| Description | E-value | Query Range |
Subject Range |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
|
0.0 | [1..384] | [1..384] |
|
Region A: Residues: [1-157] |
1 11 21 31 41 51
| | | | | |
1 MAAVQMDPEL AKRLFFEGAT VVILNMPKGT EFGIDYNSWE VGPKFRGVKM IPPGIHFLHY 60
61 SSVDKANPKE VGPRMGFFLS LHQRGLTVLR WSTLREEVDL SPAPESEVEA MRANLQELDQ 120
121 FLGPYPYATL KKWISLTNFI SEATVEKLQP ENRQICA
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [158-238] |
1 11 21 31 41 51
| | | | | |
1 FSDVLPVLSM KHTKDRVGQN LPRCGIECKS YQEGLARLPE MKPRAGTEIR FSELPTQMFP 60
61 EGATPAEITK HSMDLSYALE T
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [239-384] |
1 11 21 31 41 51
| | | | | |
1 VLNKQFPSSP QDVLGELQFA FVCFLLGNVY EAFEHWKRLL NLLCRSEAAM MKHHTLYINL 60
61 ISILYHQLGE IPADFFVDIV SQDNFLTSTL QVFFSSACSI AVDATLRKKA EKFQAHLTKK 120
121 FRWDFAAEPE DCAPVVVELP EGIEMG
|
| Detection Method: |
Shown below is our most confident prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.