| Protein: | AKH1_ARATH |
| Organism: | Arabidopsis thaliana |
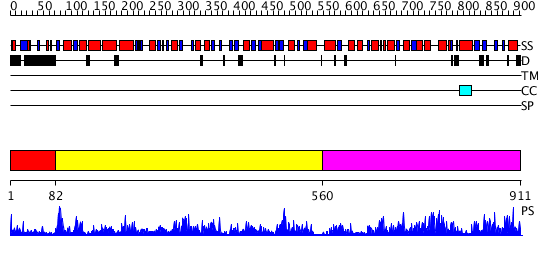
| Length: | 911 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
No multiple sequence alignment data found for AKH1_ARATH.
|
Region A: Residues: [1-81] |
1 11 21 31 41 51
| | | | | |
1 MPVVSLAKVV TSPAVAGDLA VRVPFIYGKR LVSNRVSFGK LRRRSCIGQC VRSELQSPRV 60
61 LGSVTDLALD NSVENGHLPK G
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [82-559] |
1 11 21 31 41 51
| | | | | |
1 DSWAVHKFGG TCVGNSERIK DVAAVVVKDD SERKLVVVSA MSKVTDMMYD LIHRAESRDD 60
61 SYLSALSGVL EKHRATAVDL LDGDELSSFL ARLNDDINNL KAMLRAIYIA GHATESFSDF 120
121 VVGHGELWSA QMLAAVVRKS GLDCTWMDAR DVLVVIPTSS NQVDPDFVES EKRLEKWFTQ 180
181 NSAKIIIATG FIASTPQNIP TTLKRDGSDF SAAIMSALFR SHQLTIWTDV DGVYSADPRK 240
241 VSEAVVLKTL SYQEAWEMSY FGANVLHPRT IIPVMKYDIP IVIRNIFNLS APGTMICRQI 300
301 DDEDGFKLDA PVKGFATIDN LALVNVEGTG MAGVPGTASA IFSAVKEVGA NVIMISQASS 360
361 EHSVCFAVPE KEVKAVSEAL NSRFRQALAG GRLSQIEIIP NCSILAAVGQ KMASTPGVSA 420
421 TFFNALAKAN INIRAIAQGC SEFNITVVVK REDCIRALRA VHSRFYLSRT TLAVGIIG
|
| Detection Method: | |
| Confidence: | 114.0 |
| Match: | 3c1mA |
| Description: | No description for 3c1mA was found. |
|
Region A: Residues: [560-911] |
1 11 21 31 41 51
| | | | | |
1 PGLIGGTLLD QIRDQAAVLK EEFKIDLRVI GITGSSKMLM SESGIDLSRW RELMKEEGEK 60
61 ADMEKFTQYV KGNHFIPNSV MVDCTADADI ASCYYDWLLR GIHVVTPNKK ANSGPLDQYL 120
121 KIRDLQRKSY THYFYEATVG AGLPIISTLR GLLETGDKIL RIEGIFSGTL SYLFNNFVGT 180
181 RSFSEVVAEA KQAGFTEPDP RDDLSGTDVA RKVTILARES GLKLDLEGLP VQNLVPKPLQ 240
241 ACASAEEFME KLPQFDEELS KQREEAEAAG EVLRYVGVVD AVEKKGTVEL KRYKKDHPFA 300
301 QLSGADNIIA FTTKRYKEQP LIVRGPGAGA QVTAGGIFSD ILRLAFYLGA PS
|
| Detection Method: | |
| Confidence: | 67.0 |
| Match: | 1ebfA |
| Description: | Homoserine dehydrogenase |
Matching Structure (courtesy of the PDB): |
|