| Protein: | ACA8_ARATH |
| Organism: | Arabidopsis thaliana |
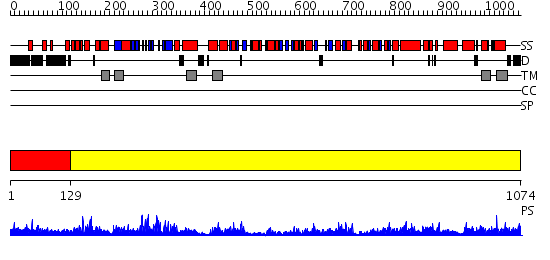
| Length: | 1074 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for ACA8_ARATH.
| Description | E-value | Query Range |
Subject Range |
|
|
883.0 | [0..1] | [1072..1] |
|
Region A: Residues: [1-128] |
1 11 21 31 41 51
| | | | | |
1 MTSLLKSSPG RRRGGDVESG KSEHADSDSD TFYIPSKNAS IERLQQWRKA ALVLNASRRF 60
61 RYTLDLKKEQ ETREMRQKIR SHAHALLAAN RFMDMGRESG VEKTTGPATP AGDFGITPEQ 120
121 LVIMSKDH
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [129-1074] |
1 11 21 31 41 51
| | | | | |
1 NSGALEQYGG TQGLANLLKT NPEKGISGDD DDLLKRKTIY GSNTYPRKKG KGFLRFLWDA 60
61 CHDLTLIILM VAAVASLALG IKTEGIKEGW YDGGSIAFAV ILVIVVTAVS DYKQSLQFQN 120
121 LNDEKRNIHL EVLRGGRRVE ISIYDIVVGD VIPLNIGNQV PADGVLISGH SLALDESSMT 180
181 GESKIVNKDA NKDPFLMSGC KVADGNGSML VTGVGVNTEW GLLMASISED NGEETPLQVR 240
241 LNGVATFIGS IGLAVAAAVL VILLTRYFTG HTKDNNGGPQ FVKGKTKVGH VIDDVVKVLT 300
301 VAVTIVVVAV PEGLPLAVTL TLAYSMRKMM ADKALVRRLS ACETMGSATT ICSDKTGTLT 360
361 LNQMTVVESY AGGKKTDTEQ LPATITSLVV EGISQNTTGS IFVPEGGGDL EYSGSPTEKA 420
421 ILGWGVKLGM NFETARSQSS ILHAFPFNSE KKRGGVAVKT ADGEVHVHWK GASEIVLASC 480
481 RSYIDEDGNV APMTDDKASF FKNGINDMAG RTLRCVALAF RTYEAEKVPT GEELSKWVLP 540
541 EDDLILLAIV GIKDPCRPGV KDSVVLCQNA GVKVRMVTGD NVQTARAIAL ECGILSSDAD 600
601 LSEPTLIEGK SFREMTDAER DKISDKISVM GRSSPNDKLL LVQSLRRQGH VVAVTGDGTN 660
661 DAPALHEADI GLAMGIAGTE VAKESSDIII LDDNFASVVK VVRWGRSVYA NIQKFIQFQL 720
721 TVNVAALVIN VVAAISSGDV PLTAVQLLWV NLIMDTLGAL ALATEPPTDH LMGRPPVGRK 780
781 EPLITNIMWR NLLIQAIYQV SVLLTLNFRG ISILGLEHEV HEHATRVKNT IIFNAFVLCQ 840
841 AFNEFNARKP DEKNIFKGVI KNRLFMGIIV ITLVLQVIIV EFLGKFASTT KLNWKQWLIC 900
901 VGIGVISWPL ALVGKFIPVP AAPISNKLKV LKFWGKKKNS SGEGSL
|
| Detection Method: | |
| Confidence: | 1000.0 |
| Match: | 1iwoA |
| Description: | Calcium ATPase, transduction domain A; Calcium ATPase, catalytic domain P; Calcium ATPase; Calcium ATPase, transmembrane domain M |
Matching Structure (courtesy of the PDB): |
|