| Protein: | gi|124800689, gi... |
| Organism: | Plasmodium falciparum 3D7 |
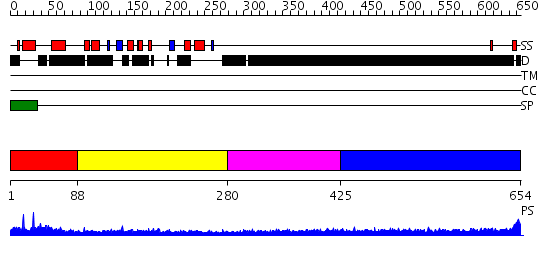
| Length: | 654 amino acids |
| Reference: | Drew K, et al. (2011) The proteome folding project: Proteome-scale prediction of structure and function. Genome Res. 2011 Sep 16 |
Listed below are up to the top 10 sequence alignment matches, by species, for the PSI-BLAST search against the protein sequence for gi|124800689, gi....
| Description | E-value | Query Range |
Subject Range |
|
|
221.0 | [0..1] | [654..1] |
|
|
211.0 | [0..1] | [654..1] |
|
|
208.0 | [0..1] | [654..1] |
|
|
208.0 | [0..47] | [649..699] |
|
|
207.0 | [0..45] | [646..436] |
|
|
200.0 | [0..71] | [648..40] |
|
Region A: Residues: [1-87] |
1 11 21 31 41 51
| | | | | |
1 MKSFKNKNTL RRKKAFPVFT KILLVSFLVW VLKCSNNCNN GNGSGDSFDF RNKRTLAQKQ 60
61 HEHHHHHHHQ HQHQHQAPHQ AHHHHHH
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [88-279] |
1 11 21 31 41 51
| | | | | |
1 GEVNHQAPQV HQQVHGQDQA HHHHHHHHHQ LQPQQPQGTV ANPPSNEPVV KTQVFREARP 60
61 GGGFKAYEEK YESKHYKLKE NVVDGKKDCD EKYEAANYAF SEECPYTVND YSQENGPNIF 120
121 ALRKRFPLGM NDEDEEGKEA LAIKDKLPGG LDEYQNQLYG ICNETCTTCG PAAIDYVPAD 180
181 APNGYAYGGS AH
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [280-424] |
1 11 21 31 41 51
| | | | | |
1 DGSHGNLRGH DNKGSEGYGY EAPYNPGFNG APGSNGMQNY VPPHGAGYSA PYGVPHGAAH 60
61 GSRYSSFSSV NKYGKHGDEK HHSSKKHEGN DGEGEKKKKS KKHKDHDGEK KKSKKHKDNE 120
121 DAESVKSKKH KSHDCEKKKS KKHKD
|
| Detection Method: |
Shown below is our most confident de novo (Rosetta) prediction for this domain.
Click here to view all matches.
Found no confident structure predictions for this domain.
|
Region A: Residues: [425-654] |
1 11 21 31 41 51
| | | | | |
1 NEDAESVKSK KSVKEKGEKH NGKKPCSKKT NEENKNKEKT NNSKSDGSKA HEKKENETKN 60
61 TAGENKKVDS TSADNKSTNA ATPGAKDKTQ GGKTDKTGAS TNAATNKGQC AAEGATKGAT 120
121 KEASTSKEAT KEASTSKEAT KEASTSKEAT KEASTSKGAT KEASTTEGAT KGASTTAGST 180
181 TGATTGANAV QSKDETADKN AANNGEQVMS RGQAQLQEAG KKKKKRGCCG
|
| Detection Method: | |
| Confidence: | 7.0 |
| Match: | 1w9rA |
| Description: | Solution Structure of Choline Binding Protein A, Domain R2, the Major Adhesin of Streptococcus pneumoniae |
Matching Structure (courtesy of the PDB): |
|